
最近、検索結果画面への「AIによる要約」や「AIモードによる検索」が登場してきました。
そこで今回は、「ページの内容を検索エンジンへ意図した形で適切に伝える」手段の代表格である構造化データマークアップの導入について、特に初心者の方向けに実装方法をまとめてみました。
難しい構造化データの実装を助けてくれる、具体的なAIの活用方法も紹介しています。
- 構造化データマークアップとは?
- 構造化データの種類と具体例
- 構造化データマークアップの実装手順とチェック方法
- 生成AIを活用した作成ワークフロー
- 公開前の検証と公開後の監視
- 面倒なことは楽にやりたい(にんげんだもの)
構造化データマークアップとは?
Googleなどの検索エンジンやAIのクローラーなどへ、Webページの内容(記事のタイトルや著者、商品の価格、レビューなど)をこちらが意図した形で誤解なく伝えるために記述するデータ(コード)のことを指します。
そしてこの記述する内容(マークアップ)は決められた書式で用意する必要があり、「どういう風に書けばよいか」の詳細については後ほど詳しく解説します。
人間であるユーザーが見るWebページは、視覚的に変化がはっきりとしていて、比較的わかりやすい存在であると思います。
しかし機械であるクローラーやAIが見るのは人間とはちょっと違っていて、基本的にはソースであるHTMLのような「テキストを主体としたデータ」となります。
技術の進化に伴って、ユーザーに見えているのと同じようなビジュアルに(取得したHTMLなどを)さらに変換して見る、ということも可能にはなっているようですが、あくまで基本はHTML、つまりテキストなんです。また同じビジュアルを見れたとしても、人間(今までに学んだ知見などを前提として見る)と機械(明確なロジックで判断する)では受け取り方が同じになるとは限りませんよね。
そしてここで大事になるのが、機械側は「このWebページは(たぶん)こういうことなんだろう」という独自の解釈で判断をする、ということです。
つまりWebサイト運営者側からの意図が正しく伝わらず、誤解される可能性がある、というのがポイントになります。
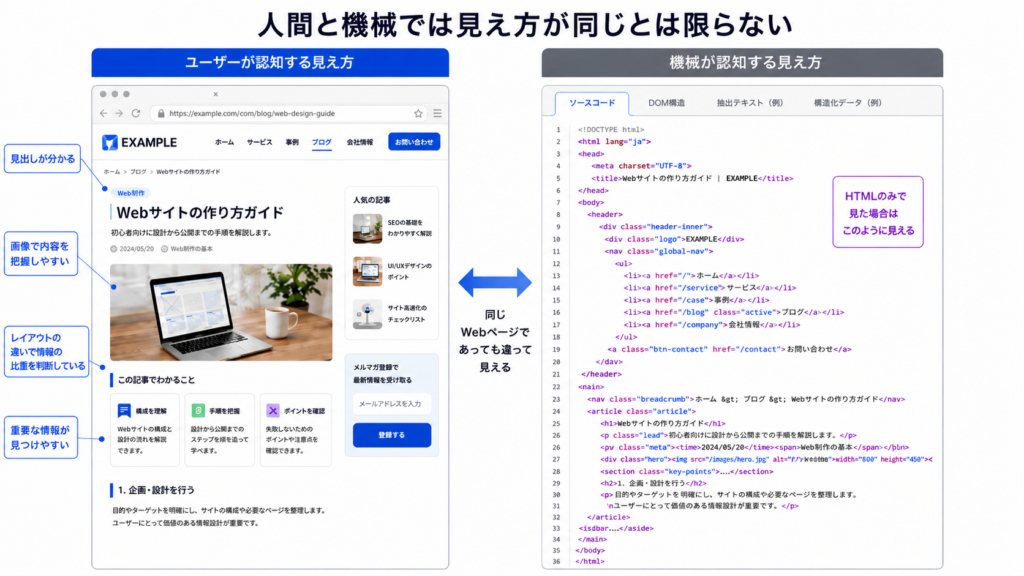
そこで、クローラーやAIなどの機械にもページの内容を誤解なく正しく理解してもらうためにWebページへ組み込むのが、構造化データのマークアップ、というわけです。
具体的には、例えばこういったものをWebページのHTMLへ含めます。
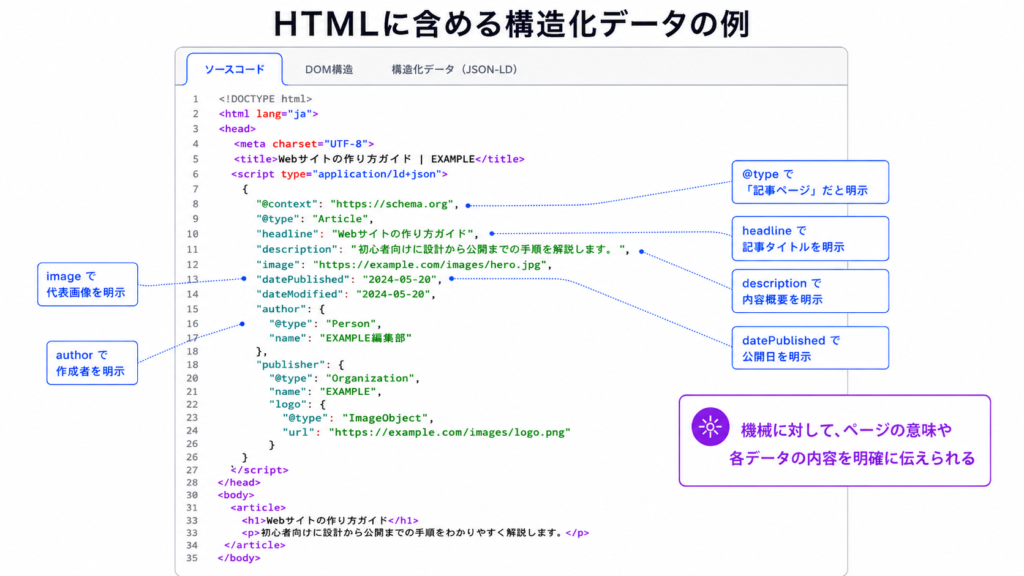
これにより、機械に対して「このWebページにはこういうデータがあって、それはこういう内容なんです」というのを、(機械側の曖昧な判断に任せるのではなく)こちらからくっきりはっきりと明確に伝えられるようになります。
構造化データマークアップのメリット
- 検索エンジンやAIのクローラーへの正確な情報伝達
- 検索結果画面でリッチスニペットが出やすくなる
なお、わりと誤解されやすいのですが、構造化データはあくまでも検索エンジンやAIのクローラーなどがWebページの内容を正確に理解するためのものであり、「伝達手段」ということこそが主目的のマークアップです。
つまりAIで引用されやすくなるわけではなく、また検索結果でのリッチスニペット表示を確約するものでもありません。
→Google Search Central:Google 検索の生成 AI 機能向けにウェブサイトを最適化する
ただ「正しくWebページを理解」した結果として、(そのページがきちんとユーザーの目的に沿っているのであれば)これらのメリットが発生する可能性が高まる、ということはあり得ます。
ですので、明確な(実用的な)メリットを求めて設置するものというよりも、「なんか効果あればいいな」ぐらいの気持ちで設置する、のが良いかと思います。
構造化データの種類と具体例
構造化データのマークアップには、たくさんの種類と、3つの書き方が存在しています。
「こういうデータがWebページに存在しています」というのが種類で、書き方はそれをどう伝えるか、という方法の話ですね。
この種類というのは、例えば「パンくずリスト」であったり、ブログ記事ページなどであれば「記事」であったり、ECサイトの商品詳細ページであれば「商品」であったり、といった具合です。
定義されている種類の中から、それぞれのWebページに含まれているコンテンツ的に設置して良さそうなものを探してHTMLへ挿入する、という選び方をします。
なお前提として、構造化データは「ページのコンテンツを正しく機械へ伝えるためのもの」です。なので、「ユーザーに見えないデータ(=ページのコンテンツではない)を含んではいけない」ということを念頭においてください。でないと、「検索エンジン向けにSEO目的で隠しテキストを設置する」みたいな、いわゆるSEOスパムと同じように扱われてしまう危険性があります。
→Google Search Central:構造化データに関する一般的なガイドライン
よく使われる種類(パンくずリストや記事、商品など)
構造化データの種類は、実はめちゃくちゃたくさんあります。
それらはSchema.orgというWebサイトで仕様がかっちりと掲載されてるんですが、ほんとたくさんあります。
構造化データのマークアップは「Webページの内容を誤解なく伝えるようにするためのもの」ですので、基本的には「構造化データのマークアップは設置すれば設置するだけ良い」です。
しかし、種類が多すぎるため、設置できるもの全部を実装しようとすると労力がとんでもないことになります。
そこでオススメなのが、Google Search Centralにある「Google 検索がサポートする構造化データ マークアップ」に掲載されている構造化データのみ実装する、という判断です。
これは検索エンジン(Google)が明示的に「これらの構造化データを設置していればリッチな見え方の検索結果(リッチリザルト)として活用することもありますよ」というのをまとめたものになっています。
いくつか、特に設置しやすいWebページの多いものを例に挙げて簡単に紹介しますね。
パンくずリスト (BreadcrumbList)
- 対象ページ
- サイトTOP以外の全ページ(※パンくずリストがページ内に存在していることが条件)
- 公式ヘルプ
- パンくずリスト
とにかく出番の多い、最も汎用的な構造化データです。
いまどきのWebサイトであれば基本的にパンくずリスト(「HOME > 大カテゴリ > 中カテゴリ > 小カテゴリ > 現在地」みたいになってるナビゲーション)はページ内のどこかしらに設置されているでしょうから、パンくずリストを設置しないサイトTOPページ以外の全ページで設置できることがほとんどです。
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [{
"@type": "ListItem",
"position": 1,
"name": "ホーム",
"item": "https://example.com/"
},{
"@type": "ListItem",
"position": 2,
"name": "ブログ",
"item": "https://example.com/blog/"
},{
"@type": "ListItem",
"position": 3,
"name": "記事タイトル",
"item": "https://example.com/blog/article-123"
}]
}
</script>記事 (Article / NewsArticle / BlogPosting)
- 対象ページ
- ブログ記事やニュース記事、などの読み物系コンテンツの詳細ページ
- 公式ヘルプ
- 記事
ニュース記事やブログ記事など、読み物ページのためのマークアップです。
タイトル、公開日、著者情報、画像などを指定します。
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "記事のタイトル",
"image": [
"https://example.com/photos/1x1/photo.jpg",
"https://example.com/photos/4x3/photo.jpg",
"https://example.com/photos/16x9/photo.jpg"
],
"datePublished": "2025-12-01T08:00:00+09:00",
"dateModified": "2025-12-05T09:20:00+09:00",
"author": [{
"@type": "Person",
"name": "執筆者名",
"url": "https://example.com/profile/author"
}]
}
</script>商品 (Product)
- 対象ページ
- ECサイトなどの商品詳細ページ
- 公式ヘルプ
- ショッピング
ECサイトではほぼ必須のマークアップです。
ただ「商品情報だけ(商品スニペット)」や「販売もしている場合の商品情報(販売者のリスティング)」、「バリエーションのある商品情報(パターン)」など、Webページの作りやコンテンツによっていくつかパターンがあるので、ちょっと難易度は高いです。
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Product",
"name": "商品の名前",
"image": [
"https://example.com/photos/1x1/photo.jpg"
],
"description": "商品の説明文です。",
"brand": {
"@type": "Brand",
"name": "ブランド名"
},
"offers": {
"@type": "Offer",
"url": "https://example.com/product/123",
"priceCurrency": "JPY",
"price": "5000",
"availability": "https://schema.org/InStock"
}
}
</script>3つの書式(おすすめはJSON-LD)
構造化データのマークアップは、3つの書き方があります。
現在Googleが推奨しているのは、3つ目のJSON-LDという形式ですね(前述で出てきた各例もJSON-LDでした)。
- RDFa
- Microdata
- JSON-LD オススメ!
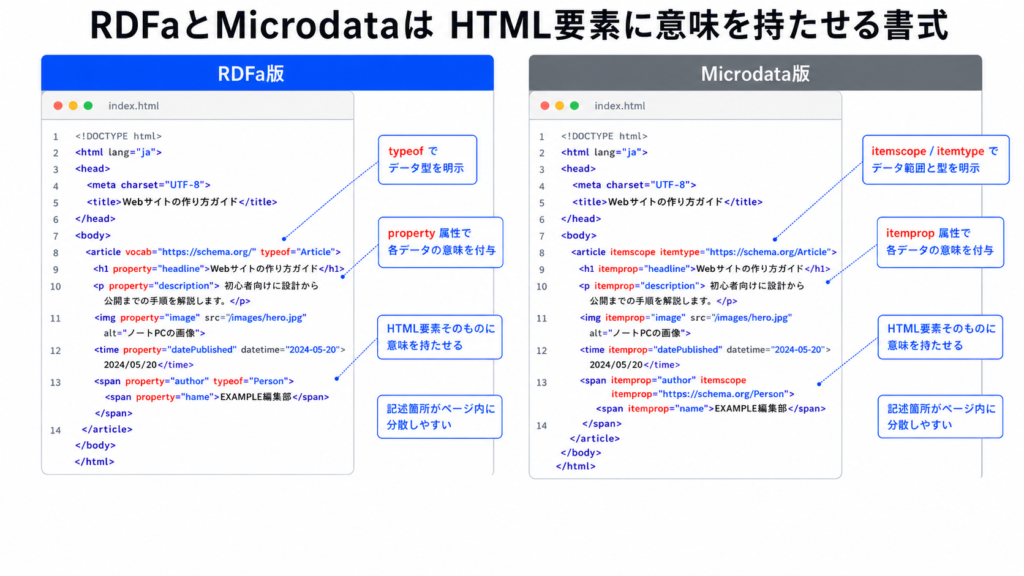
前2つのRDFaとMicrodataは、それぞれ「HTML内の該当データの箇所へ『これは〇〇のデータです』というのを示す属性値を追加」する手法です。
こう聞くとわかりやすく感じることもあり、構造化データの初期のころまでは、こちらが主流だったと思います。
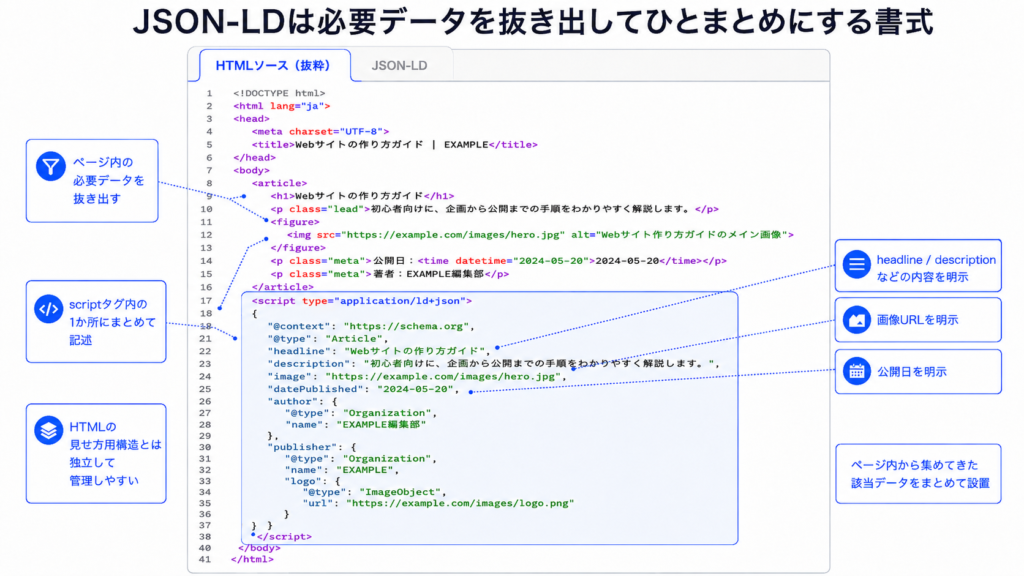
で、逆に現在最も推奨されている最後のJSON-LDは「scriptタグでページ内の1か所に必要データをまとめる」手法です。
すでにページ内にコンテンツとして存在しているデータと同じものを複製することになって「それってなんか二度手間っぽくなりません?」となるかもしれませんが、ところがどっこい、この方法が最も管理が楽になるんです。
前述のとおり、以前はHTMLタグの中に属性として埋め込むMicrodataなどが使われていましたが、管理が煩雑になりがちでした。
また、ページの見せ方によってHTMLはいろいろ複雑になりがちで、結果として「構造化データとして必要な親子構造」をHTMLで保てないケースも起こりがちで、HTMLの制作の難易度にまで影響を及ぼしていたんです。
その点、JSON-LDはHTML内の実際の該当データの箇所とは独立させた場所へ、データを記述します。つまり「HTMLの親子構造と構造化データの親子構造」を切り離せるようになったんです。
これは他にもメリットがありまして。
- 人間が見ても分かりやすい
- HTMLの中で1か所にまとまってるので、探しやすく、把握しやすい
(Microdataなどでは複数のHTML要素に散らばっているため、目視だと非常に探しにくい)
- HTMLの中で1か所にまとまってるので、探しやすく、把握しやすい
- 再利用しやすい
- JavaScriptでJSON-LDをまるまる取得することもできるため、例えばGTMで構造化データを取得して、変数として計測に活用することも可能
ちなみにJSON-LDの場合、HTMLのどこかに置けばOKです。bodyタグ内とかでも問題はありませんが、ページのいわゆるメタデータにあたるので慣例的にはheadタグ内の末尾などが定番位置ですね。
他にも実装方法として、GTMを使って後からWebページへ挿入設置させる方法もありますが、可能であればHTMLファイル自体に設置することを強くおすすめします。
GTM経由で設置する場合、設置処理完了のタイミングによっては検索エンジンに正しく認識されないリスクがあったり、そもそも変数設定はJSを使う必要が多く難易度も優しくはありませんので、設定を誤る可能性もあるためです。
メタデータという性質上、最初からHTMLに含まれている状態がベストプラクティスと言えます。
構造化データマークアップの実装手順とチェック方法
大まかな作業の流れとしては、下記のようになります。
- 設置する対象ページをよく見る(ページの種類や掲載コンテンツ内容など)
- 構造化データの一覧をチェックし、適切な種別を探す(Google Search Centralでガイドラインと必須プロパティをチェック)
- 設置する構造化データのサンプルをコピーして、データの値を対象ページのものへ書き換え
- リッチリザルトテストツールで書式に間違いがないか確認
- CMSのテンプレートなどへ、3で用意したサンプルを基に、構造化データのマークアップを設置
- リリース後、Google Search Consoleで構造化データが認識されたかを確認
特に前半部分について、具体的にみていきましょう。
1. 設置する対象ページをよく見る
前述でも触れましたが、構造化データのマークアップには「ユーザーに見えないデータ(=ページのコンテンツではない)を含んではいけない」という大前提があります。
これを判断するため、「何のためのページか」「どんなコンテンツ(データ)が掲載されているか」を特にチェックしておきましょう。
ちなみにですが、ユーザーが認知可能な状態であれば、ページのコンテンツとして構造化データに含めることは可能です。
例えば、以下などは問題ありません。
- パンくずリストに対して、TOPや親階層などのページのURL
- 普通のリンクが張られたパンくずリストであれば、リンクURLをユーザーが識別可能な状態であるため、パンくずリストの構造化データに含めても良い。
- 普通のリンクが張られたパンくずリストであれば、リンクURLをユーザーが識別可能な状態であるため、パンくずリストの構造化データに含めても良い。
- アコーディオンUIなどに含まれるデータ
- (クリックやタップによって開閉するタイプのUI)
- ユーザーの操作によって見ることが可能なデータであれば(ユーザーが見ることができるので)、構造化データに含めても良い。
逆に言うと「ユーザーがページ内の操作などを行っても見ることができない(認知できない)データ」を含めてはダメ、ということですね。
2. 構造化データの一覧をチェックし、設置が適していそうな種別を探す
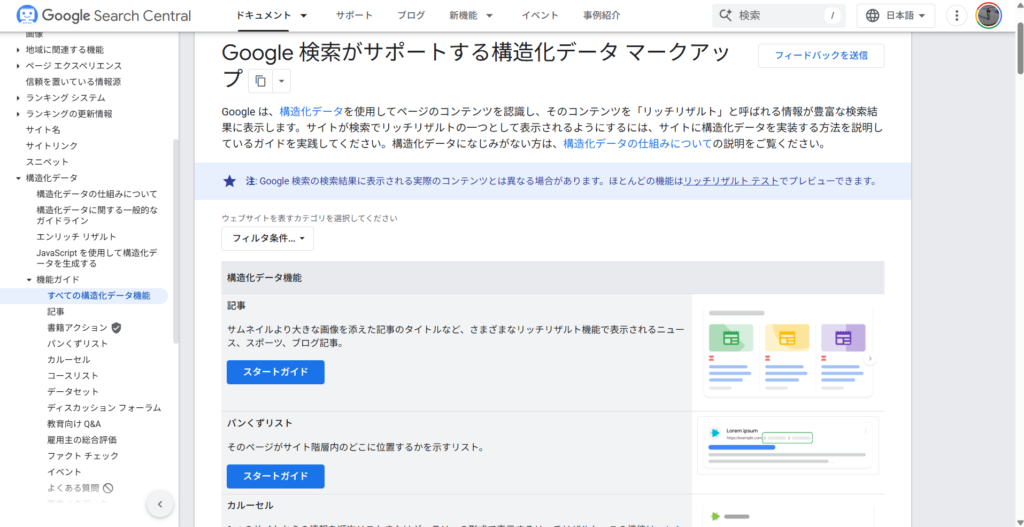
「Google 検索がサポートする構造化データ マークアップ」にはGoogleが対応を明言している構造化データの種類の一覧があります。
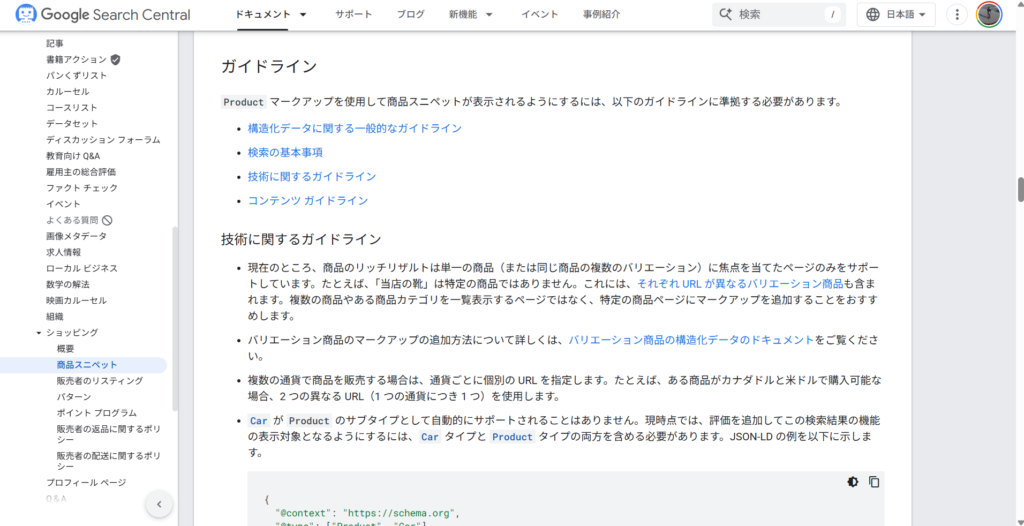
それぞれには「こういうページであれば設置していいよ」などをまとめたガイドラインと、「設置するなら絶対このデータを含めてね(=このデータがないなら設置はNG)」を示した必須プロパティの表が掲載されています。
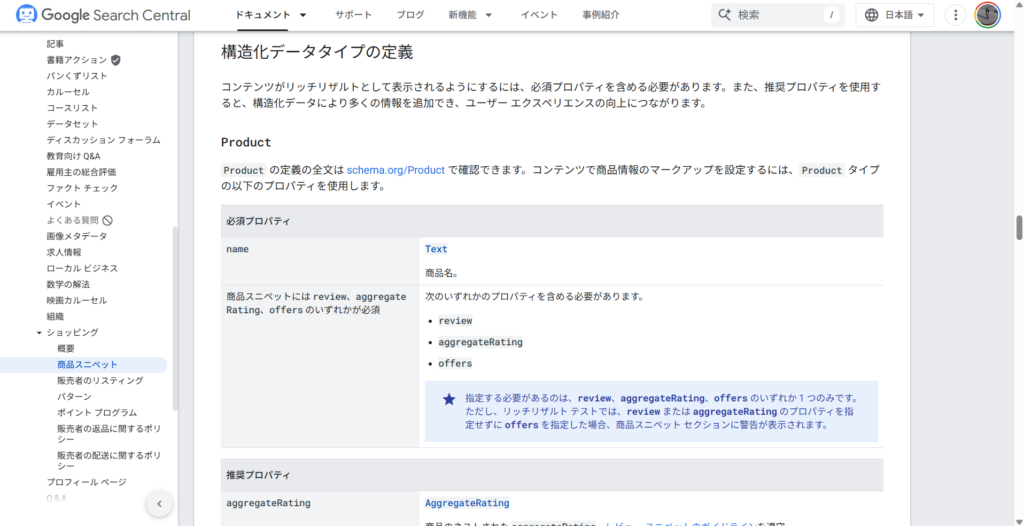
必須プロパティは名前の通り「絶対に必要な(これがないと成立しない)データ」ですので、ページにこれらが存在していない場合、その構造化データは利用できません。
逆に推奨プロパティは「なくてもよい(けどあった方が良い)データ」ですので、もしページに該当のデータが存在している場合は、必須プロパティだけでなく推奨プロパティも含めるようにしましょう。
3. 設置する構造化データのサンプルをコピーして、データの値を対象ページのものへ書き換え
設置が可能そうであれば、その構造化データのサンプルをコピーします。
ガイドラインなどと同じく、詳細ページ内に「例」としてサンプルのHTMLが掲載されていますので、それを使いましょう。
JSON-LDで設置する場合、例の中にあるscriptタグがJSON-LDの書式にあたります。
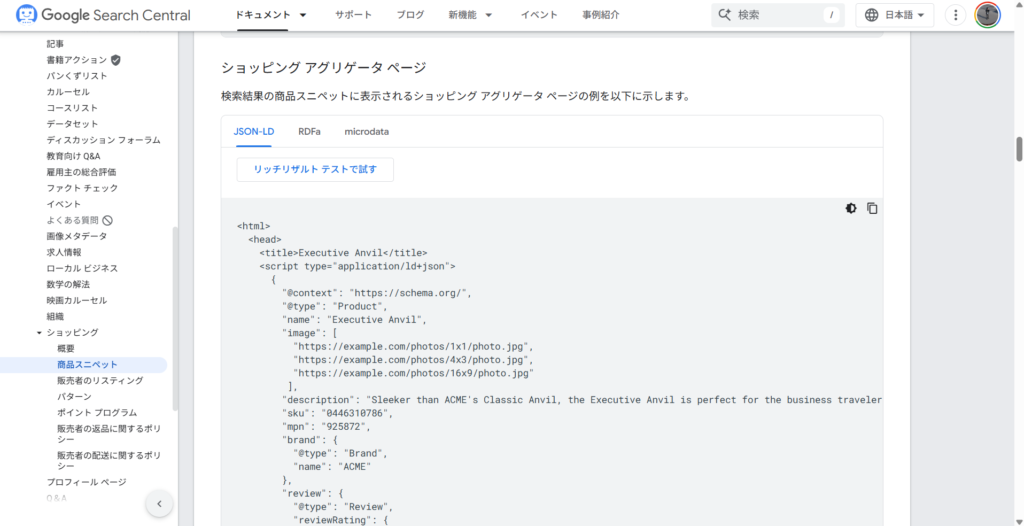
scriptタグをテキストエディタなどへコピーします。JSON-LDの見方は「"プロパティ名": "データ"」という書き方が基本となっていて、そのほかに下記のようなルールがあります。
- 「
@」で始まる名前のプロパティは構造化データの定義に必要なもの - 「
@context」は「https://schema.org」で完全固定
(https://schema.orgで定義された規格の名前などを使ってますよ、という宣言) - 「
@type」は構造化データの種類を指定する箇所 - プロパティ名は必須プロパティや推奨プロパティなどに記載されている「決められた名前」を使う必要がある
- 後続のデータがある場合は末尾に「
,」を記述 - データをさらに入れ子にする場合は「
{~~}」のように書くことで複数のプロパティとデータを持たせられる - データを複数持たせる場合は「
[~~, ~~, ~~]」のように書くことで、複数のデータを持たせられる
上記を踏まえたうえで、プロパティの表を見ながら、該当するプロパティのデータとして対象プロパティのデータを入れていきましょう。
そして対象ページに存在していない推奨プロパティについては、行ごと削除してください。
同様に、サンプルにはないけど対象ページには存在していて推奨プロパティとしても表に載っているものがあれば、追加しましょう。
例えば、記事の構造化データであれば、下記のようになります。
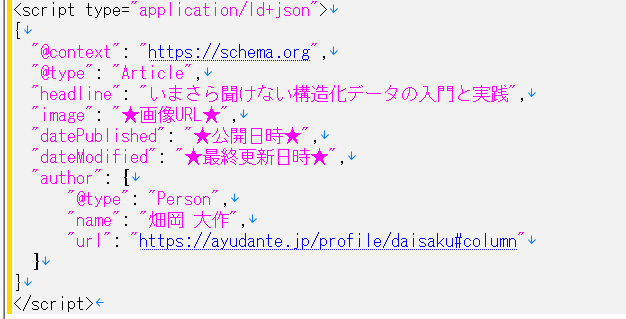
なおほとんどのWebページはCMSによる、テンプレートを使って動的に生成されていると思います。
ですので、構造化データを考える場合は「同じテンプレートでは必ず出力されるデータ」かどうか、を念頭に置く必要がありますので、その点は注意してください(例えばAというページではこのデータは出るけど、Bという別のページではこのデータは出ない、といった場合は構造化データに含められませんよね)。
生成AIを活用した作成ワークフロー
ここまでは自力で行う場合のやり方を簡単にではありますが、ご紹介しました。
ですが「正直やっぱちょっとよくわかんないし不安」という方もいらっしゃると思います。あと、「わかるけど正直面倒臭いっす」という方もいると思います。ほんとうにそう。
そういう時こそ、AIを使って楽をできるか試してみましょう。
JSON-LDの構文をゼロから手書きするのは大変ですが、ChatGPTやGeminiなどの生成AIを活用すれば、めちゃくちゃ楽に作成できます。
ただし、生成されたサンプルに対して「必ず自分で確認する」というステップを必ず入れてください。
AIは「それっぽいけど間違ったもの」を生成することもまだ(2026年5月時点)多々あり(特にGemini)、普通に嘘をついてくることも多いので、せめてその成否を判断できなければ利用はしない方が良いです。
また、もう1点だけ大きな注意事項が。
すでに公開済みのページであれば特に気にしなくても大丈夫(一般への公開情報であるため)だと思いますが、まだリリース前な未公開のページについては、残念ですがAIを使うのは控えた方が良いでしょう。
セキュリティやコンプライアンスなどが関わってくるので、外部へのデータ流出となりかねないため、そのあたりに詳しくないのであればやめておいた方が無難です。
Step 1: 適切な種類の選定
まずは、対象のページにどのような構造化データを入れられるか、をAIに相談します。
ページのURLやHTMLソースを渡し、「このページの内容に基づいて、Googleが推奨する構造化データの中から、実装すべき種類をリストアップしてください。ただし、ページ内に情報が存在しないものは除外してください」と指示します。
具体的なプロンプトは、以下のようにすると良いでしょう。
冒頭の「{URL}」の箇所と、「〇〇のページです。」の箇所を、対象ページに合わせて変えてご利用ください。
{URL}
上記URLは、〇〇のページです。
これに対して、構造化データのマークアップを設置します。
Googleが推奨する構造化データの中から、実装すべき種類をリストアップしてください。
ただし、以下を意識してください。
- 「ページ内に情報が存在しないデータ」が必須プロパティとして必要な構造化データの種類は対象外とする
- 「ページの解釈次第では設置も可能かも」な種類(グレーゾーン)は対象外とし、「このページであれば設置が推奨できる」と明確に判断できた種類のみを対象とする
- 参考情報として、「ページの種類的に設置が推奨されるが必要なデータがページに足りていない」種類や、「ページのデータ的に必須プロパティの要件は満たしているがグレーゾーンなため設置を推奨しない」種類についても、設置推奨のものとは分けてリストアップ
- 必ず最新のドキュメントの仕様を調査し、それに準じること
回答は以下のフォーマットで出力してください。
----
## 出力フォーマット
- 設置推奨の構造化データ
- {種類名}
- {Google公式ヘルプのURL}
- 推奨理由: {推奨理由}
- 各プロパティのページコンテンツ状況:
- 必須プロパティ: {OK|NG}
- 推奨プロパティ:
- {プロパティ名}: {OK|NG}
- (補足があれば)補足: {補足内容}
- 設置NGの構造化データ
- {種類名}
- {Google公式ヘルプのURL}
- 設置できない理由: {理由}出力された対象の種類や、その理由などに納得がいったら、次へ進みます。
Step 2: サンプルの生成
種類が決まったら、実際のサンプルを書いてもらいます。
先ほどのリストアップのチャットへ続けて、下記のようなプロンプトを入れると良いでしょう。
実際にWebページへ設置可能な形で、推奨構造化データをJSON-LD形式のコードを生成してください。
- ページからデータを参照する、プロパティの値欄については前後に`{`と`}`で囲み、ページから取得したデータであることを示してください
- 各プロパティのデータを、ページ内のどこから取得したか、もまとめてください
回答は以下のフォーマットで出力してください。
----
## 構造化データ
```html
{JSON-LD形式の構造化データのマークアップ}
```
## 各プロパティの取得元
- {プロパティ名}
- 取得場所: {わかりやすく端的な説明}
- HTML: {具体的なHTML上での行数など}
- (補足があれば)補足: {補足内容}Step 3: クロスチェック
可能であれば、サンプルJSON-LDを生成したのとは別のAIで、念のためファクトチェックをしましょう。
例えばChatGPTで生成したのであれば、Geminiで。Geminiで生成したのであれば、ChatGPTで、といった具合です。
異なるAIで同様の回答になるかを確認することで「単純な構文エラー」などのチェックだけでなく、「ガイドライン違反をしていないか」「嘘の出力(いわゆるハルシネーション)がされていないか」などについても二重チェックできる、というわけです(それはそれとして、最終的な判断は人間がした方が良いですがその負担を下げる手段として、二重チェックは有効です)。
具体的には、こんなプロンプトを使いましょう。
冒頭の「{URL}」と「〇〇のページです。」、および最後の方の「{生成されたJSON-LDのサンプル}」の箇所を書き換えてご利用ください。
{URL}
上記URLは、〇〇のページです。
これに対して、構造化データのマークアップを設置します。
Googleが推奨する中から、実装すべき(グレーゾーンではなく、設置が推奨される)種類の構造化データをJSON-LD形式でまとめました。
後述のサンプルに対して、以下の観点でチェックをしてください。
- ページに対して、適切な構造化データの種類であるか
- 「ページ内に情報が存在しないデータ」が必須プロパティとして必要な構造化データの種類は対象外とする
- 「ページの解釈次第では設置も可能かも」な種類(グレーゾーン)は対象外とし、「このページであれば設置が推奨できる」と明確に判断できた種類のみを対象とする
- 必ず最新のドキュメントの仕様を調査し、それに準じること
- Googleが指定する必須プロパティが間違いなく含まれていることを要確認
- Googleが指定する推奨プロパティで、含まれていないデータがページ内に存在していないか(JSON-LDへの記載漏れが発生していないか)を要確認
----
## 設置予定の構造化データ(JSON-LD)
`{`~`}`で囲われたデータがページから取得したデータの箇所となっている。
```html
{生成されたJSON-LDのサンプル}
```公開前の検証と公開後の監視
さて、サンプルのコードができたら、念のために「本当に問題ないか」をチェックしましょう。
人間の目視や考えで「この構造化データの種類で適切か」を判断お願いします、と何度か触れてきましたが、それとは別に。
テストツールを使って構文エラー(書き方が破綻していないか)が起こっていないか、も確認する必要があります。
公開前の検証:リッチリザルトテスト
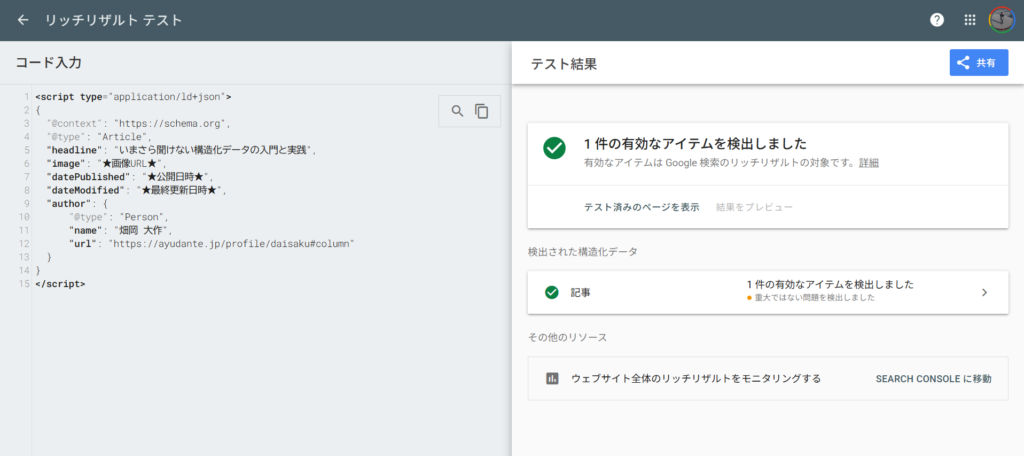
Googleが提供している公式ツール「リッチリザルトテスト」を必ず使用してください。
作成したコードスニペットを貼り付けるだけで、構文エラーがないか、必須プロパティが不足していないかを瞬時に判定してくれます。
ここでエラーが出た場合は、エラー内容をAIにコピペして修正案を出してもらうとスムーズです。
構文エラーなどがないことを確認したら、あとは実際のCMSのテンプレートなどへ組み込んで、リリースとなります。
しかし、リリース後にも1点、確認した方が良いポイントがあります。
公開後の監視:Search Console
本番公開後は、Google Search Console でステータスを確認です。
Webサイトのページに設置された構造化データが無事に検索エンジンへ認識されると、左メニューの「拡張」セクションにレポートが表示されます。
ここで「無効」などのエラーが出ていないか定期的にチェックするようにしましょう。テンプレートの改修などで意図せず構造化データが壊れてしまうことは珍しくありません。
面倒なことは楽にやりたい(にんげんだもの)
繰り返しになりますが、構造化データマークアップは「Webページの内容を正しく適切に」機械へ伝えるためのものです。
わりとリッチスニペット化されるための手段としての面が強いですが、本来はそちらはあくまで副産物で、伝えること、が主なんですよね。
とはいえ、わりと慣れない方が見ると機械語にも見えかねないのが、コードというもの。
けっこう技術的でわかりにくい作業に見えますが、こういうときこそせっかくですし、AIで楽にやっていきたいですよね。
さすがに手放しでAIに任せるのはまだまだおっかなすぎてできませんが、少しずつ、任せられることは任せていけると、たぶんより多くの人がWin-Winになれるんじゃないかな、と思います。
そのためには人間側も最低限の基本はきちんと踏まえておくことがやはりまだ必要ですので、二人三脚で進んでいきましょう。








