2023年5月24日、DemandMarkets 株式会社が主催するSEOウェビナー#DemandLiveにコガンが登壇しました。今回は「SEO 5つの論点」というタイトルで、答えのないトピックについてディスカッション形式で進行するウェビナーでした。とても濃くて面白かったので、参加していた私が要点をコラムにまとめたいと思います。5つのトピックより、今回は「クロールバジェット」を取り上げてみます。
クロールバジェットの概要とベストプラクティスについて
今回は2番目のトピック「クロールバジェットとの向き合い方」を紹介していきます。
1番目のトピック「ページネーション」はこちらにまとめています。
クロールバジェットという言葉を耳にされた方も最近は多いのではと思いますが、検索エンジンがクロールする制限、予算みたいな考え方です。
サイトごとにサーバーの強さや規模感、更新性、コンテンツの内容などからどのくらいクロールされるか、そのバジェットが決められていると言われています。
バジェットを使ってしまいますと、例えば新商品ページがなかなかクロールされない、重要なページの内容の更新に時間がかかるなどの問題が起こってしまいます。
このクロールバジェットはどのサイトにも関係するわけではありません。コガンさんによると気にする必要があるのは次の3つ。

超大規模サイト、ニュースなど更新性が高いサイト、そしてもう1つ、JSをたくさん使っていて、サーバーが弱いサイトも気にしたほうがいいと最近感じているそうです。
3つ目について補足しますと、規模が小さくても一部のページのレンダリングが完全にできていない(リソースもブロックしていないし本来レンダリングできるはず)のサイトがある。恐らくGoogleがサイトにアクセスしてたくさんのリソースをfetchする際にサーバーが弱いと応答が遅くなる、するとクローラーがレンダリングを一旦やめようということが原因でレンダリングされないページが出てくるのではないかと推測しているそうです。
室屋さんも同様の意見を述べていました。「Googleはクロールしすぎて“攻撃”になることもあるため、過剰なクロールを避けている。負荷に弱いサイトに対しては、クロールをやめてしまう」とのこと。
クロールバジェットについては少し古いですが、こちらの弊社コラムも参考にしてください。
さて、ご自身のサイトのクロール状況ですが、Search Consoleの「クロールの統計情報」を見て把握するとよいです。
サイトによって課題は全く異なります。
レスポンス別の赤枠の項目をクリックしてURLの例を見るのが重要です。

コガンさんが経験した事例を以下紹介。
前提:
レスポンス別のところに「robots.txtなし」という項目がある。
robots.txtはサブドメインごとに設置しないといけない。robots.txtに何も設定せず404を返しても問題はない。なければ全ページをクロールしていい、とGoogleは判断する。
ただ500番台のエラーが返るとGoogleはこのドメイン配下のページは全てブロックするという指示だと認識してしまう。ヘルプにも記載があるけれど、その配下のURLは何もクロールしてくれない。
事例①
リソースや画像をサブドメインに置くことが多いと思うが、そこのrobots.txtが503になっていているケースを何度か見ている。JSリソースのサブドメインのrobots.txtが503になっていた例ではサービスを全部fetchするリソースなので、サービスがたくさんあるのにGoogleがアクセスできないためにサービスが0件、サービス詳細ページも404と認識されてしまい、当然流入も大きく下がってしまった。robots.txtを直したら流入も戻ってきた。
事例②
もう1つの例は画像のサブドメインのrobots.txtが503になっていて、画像がクロールされず、広告が不承認になってしまったことがあった。
室屋さん:画像が、ショッピング広告やリッチリザルトに出ないことがあった。調べたらrobots.txtの画像制御が要因だったことがある。
次に小規模サイトです。小規模サイトはあまりバジェットを気にしなくてもいいですが、Screaming Frogで一度サイトをクロールして、自分のサイトの状況を把握しておくことがおすすめだそうです。
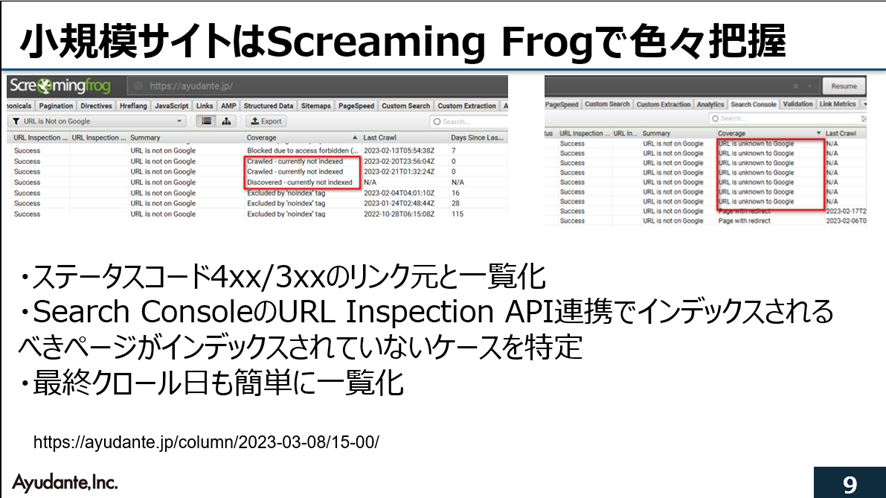
Screaming Frogはサイトをクロールして情報を一元化してくれるツール、例えば404や301のページがわかるので、そこでクロールバジェットを使わないようにしたり、404へリンクしているリンク元もわかるのですぐに修正できます。 URL Inspection APIと連携させることで、クロールはできているけれど、GoogleがインデックスしていないURL、Googleが知らないURLの検出などもできます。
最終クロール日からの日数を見ることもできます。例えば115日間クローラーがきてないページは大丈夫?など。
URL Inspection APIは1日2000件しか使えない制限もありますが、かなり活用できます。
詳しくはこちらの記事もご覧ください。
参加者からの質問
このトピックに関する視聴者の方からの質問を回答と共にいくつか紹介します。
A:Googleは最近IPを公開したので、GoogleのIPだけ(Bingも)除外するルールを設けてもいいかと思います。
たまにエンジニアさんの判断でブロックして流入が減ることもあるけれど、そのあとしばらくクロールが戻らないので(Googleは戻してよいか少しずつ増やしながら試すので)、webサーバー側の設定を見直してもらうのがいいと思います。

A:クロールよりインデックスの状況を見ています。クロールの細かいところにとらわれず、課題があるときだけ見に行くことが多いです。
モニタリングはサーチコンソールのクロールの統計情報を定期的にモニタリングすることが多いです。
インデックスと順位のモニタリングだけでも課題に気づくことが多いです。
室屋さん:個人的な経験では、クロールのモニタリングはあまり意味がなかった。施策を打てば一気に改善するし、何もしなければ変わらないので。ダッシュボードを作ってステータスコードなどをまとめたり、クロール率を見られるようにしていました。
サステナブルクロールについて、最近インデックスが遅いことがあります。
新しいページがインデックスされない、課題がないのにインデックスされない、リクエストを送ればすぐインデックスされる、ページを一度削除してアップするとすぐインデックスされるなど。
海外でも数年前からクロール頻度が下がっていることは言われていますよね。
室屋さんの補足によると、
10年以上前から二酸化炭素排出量などはGoogle内でもKPIになっているとのこと。
次のコラムでは「サイトマップの運用どうしてます…?」を取り上げたいと思います。
今回の一連のコラム:
1番目のトピック「ページネーション」はこちら
2番目のトピック「クロールバジェット」(本コラム)
3番目のトピック「サイトマップ」はこちら
4番目のトピック「E-E-A-T」はこちら
5番目のトピック「様々なSEOのQ&A」はこちら





![いちばんやさしい新しいSEOの教本 第2版 検索に強いサイトの作り方[MFI対応]](https://ayudante.jp/wp-content/uploads/2018/06/seovol2_book-151x214.jpg)


![コンテンツSEOで新たな顧客層の獲得に成功! ─カタログ通販の「セシール」 [ ネットショップのためのSEO施策ゼミナール 第12回 ]](https://ayudante.jp/wp-content/uploads/2014/10/201408ezawa_nettan.png)