Screaming Frog SEO Spiderとは、SEOに関連する情報を一覧化できる診断用のクローラーツールです。有料版ではGoogleアナリティクスやSearch Consoleなど外部ツールとの連携も提供されており、Search ConsoleのURL Inspection API(Search Consoleの「URL検査」のデータを取得できるAPI)との連携もあります。
この記事ではScreaming Frog とURL Inspection APIの連携方法、そして活用例やAPIの制限などについて紹介します。
Screaming FrogでURL Inspection APIを連携する方法
Screaming FrogとSearch Consoleの一般的な連携方法については過去の記事で詳細に解説していますが、始めに「Configuration」>「API Access」>「Google Search Console」よりデータを確認したいプロパティが紐づいているアカウントと連携を行い、対象プロパティを選定します。
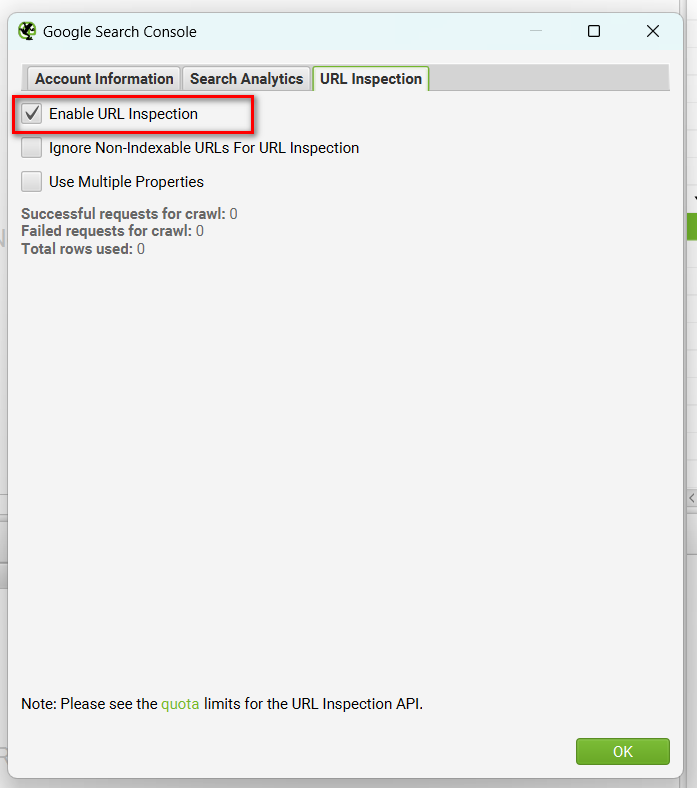
「URL Inspection」タブにて「Enable URL Inspection」にチェックを入れると、URL Inspection APIとの連携が有効化され、クロールの際にURL検査ツールのデータがScreaming FrogのSearch Consoleレポートに表示されるようになります。
URL検査関連項目のレポートと活用例
Search Consoleとの連携とURL Inspectionデータ取得の有効化が行われ、サイトがクロールされれば、Search Consoleのデータが左側のメインレポートの「Search Console」タブに表示されます。
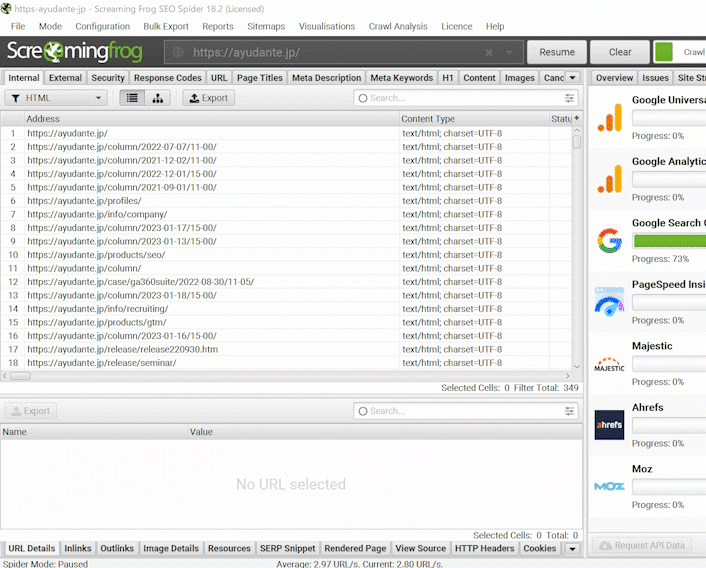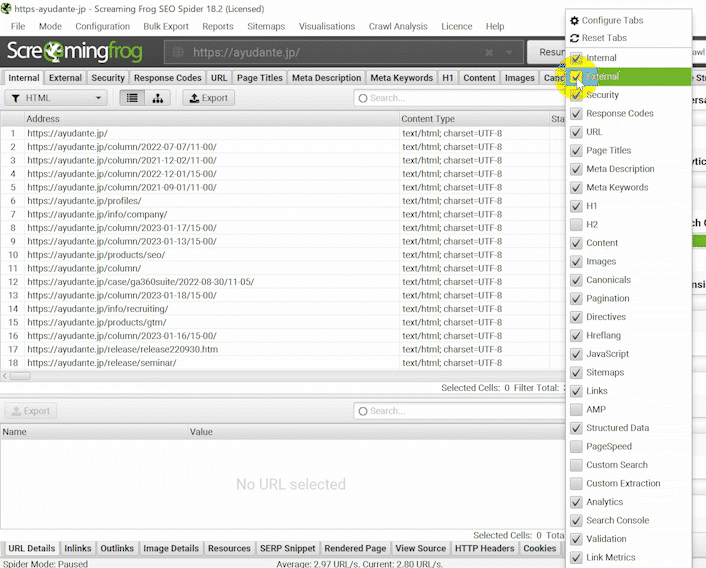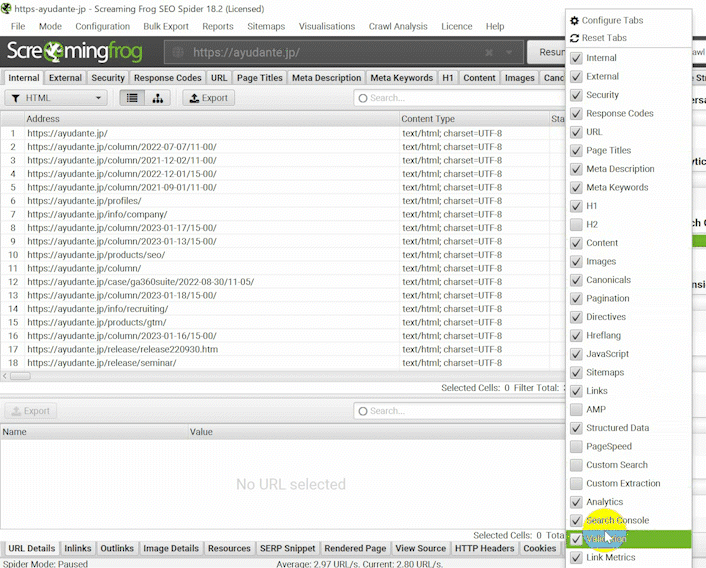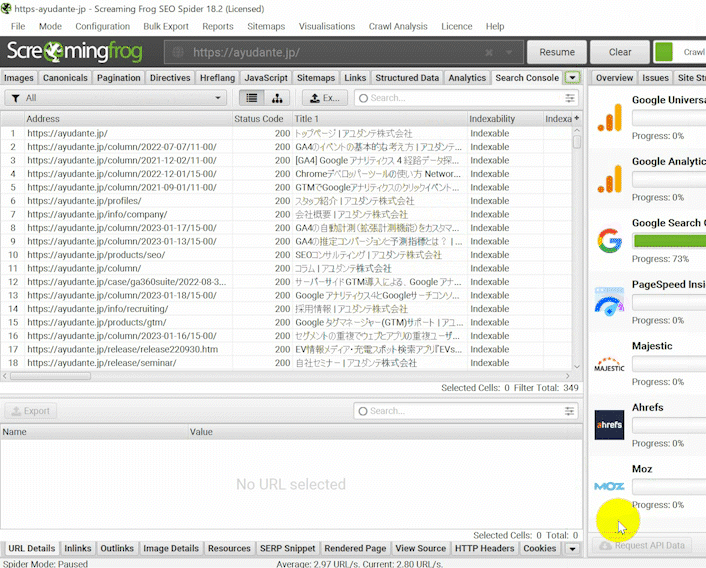
このレポートでURL検査と関連する以下のフィルターが使えるようになります。
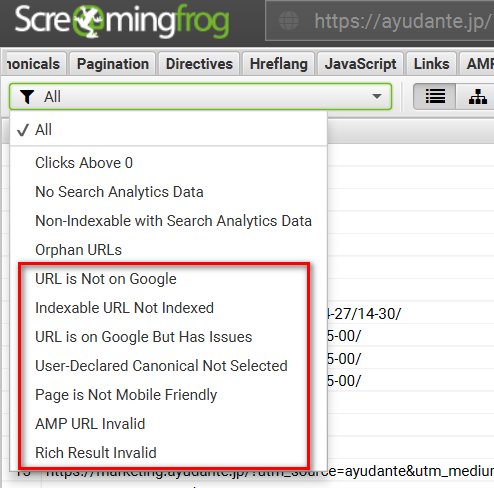
フィルターを使ったデータの活用例をいくつか紹介していきます。
インデックス登録されていないURLの確認
「URL is Not on Google」ではリダイレクト、404ステータスコード、noindexタグ設定など想定内の理由でインデックス登録されていないURLと、「Discovered – currently not indexed」(検出 – インデックス未登録)と「Crawled – currently not indexed」(クロール済み – インデックス未登録)など想定内の理由がなくインデックス登録されていないURLを確認できます。
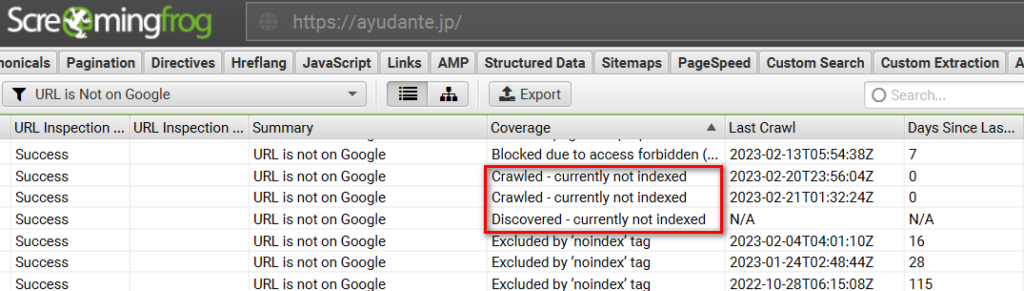
除外されているURLに想定外のものが入っていないか確認できるため、インデックス登録の問題の発見に役立ちます。
インデックス登録されているが課題があるURLの確認
「URL in on Google But Has Issues」ではインデックス登録されているが、モバイルユーザビリティ、AMPやリッチリザルトの課題があり、最適に表示されていない可能性があるURLに絞ることができます。
更に、「Page Is Not Mobile Friendly」「AMP URL Is Invalid」「Rich Result Invalid」のフィルターではそれぞれの課題があるURLに絞り込めます。課題があった場合はその課題の種類(例えばモバイルフレンドリーのエラーやリッチリザルトの警告)も確認できます。

Canonical設定が無視されたURLの確認
「User-Declared Canonical Not Selected」ではそのURLに実際に入っているCanonicalタグの値とGoogleが正規URLとして選定したURLが一致しないURLに絞り込むことができますので、正規化の課題の発見に役立ちます。
デフォルトのフィルターも便利ですが、更にデータをExcelなどにエクスポートして、自身でデータを加工することで他にもさまざまな活用方法が生まれます。
ページ群ごとのインデックス率を確認する
例えばカテゴリ(/category/配下)などページ群別にインデックス率を確認することで、インデックス登録に課題が発生しているページ群がないかを確認することができます。
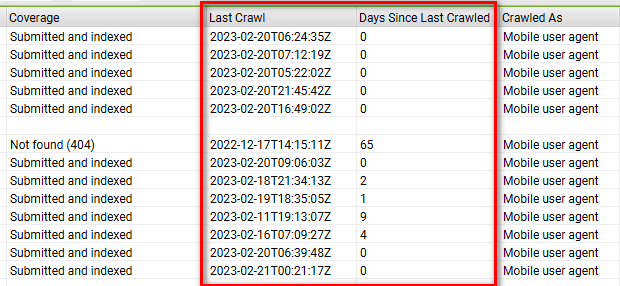
最後にクロールされた日付を確認する
最終のクロール日時と、最終クロールからの日数という便利な項目があるため、頻繁に更新しているコンテンツにGooglebotが定期的に来ているか、なかなかクローラーがまわってこないページ群がないかなどを確認することができます。
Googleに検出されていないURLの確認
「Coverage」のステータスには「URL is unknown to Google」の項目があり、Screaming Frogはクロールしたけれども、Googleは検出していないURLを抽出することができます。
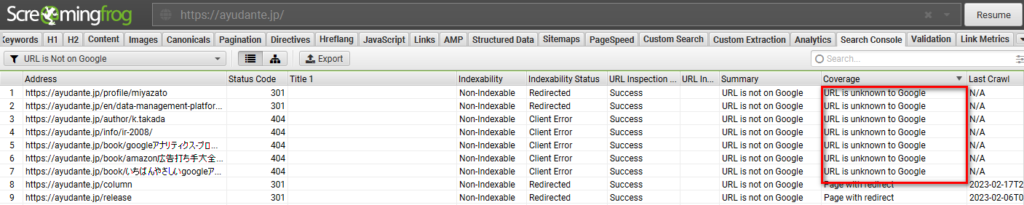
こちらはクローラーツールならではの項目で、本来Googleにクロールしてもらいたいけど現在検出されていないURLがないかの確認に役立ちます。
URL Inspection APIの制限とその緩和方法
URL Inspection APIには1プロパティあたり1日2000件しか取得できないという制限があります。
Screaming Frogが最初にクロールした2000件のURLに対してURL検査ツールのデータを取得しますので、デフォルトではクロール起点となるページからより少ない遷移数でクロールできるURLが対象になります。
そのため、URL数が多いサイトでは、優先的にクロールしてもらうURLを調整すること、または対象URL件数を増やす、後日追加のデータを取得するなど工夫が必要となります。
優先的にクロールしてもらうURLを指定する
以下、優先的にクロールしてもらうURLもしくは逆に除外するURLを指定するいくつかの方法を紹介します。
インデックス登録不可URLを除外する
「URL Inspection」連携の設定にある「Ignore Non-Indexable URLs For URL Inspection」にチェックを入れることで、noindexやcanonicalタグが設定されているなどの理由でインデックス登録されないはずのURLを除外することができます。
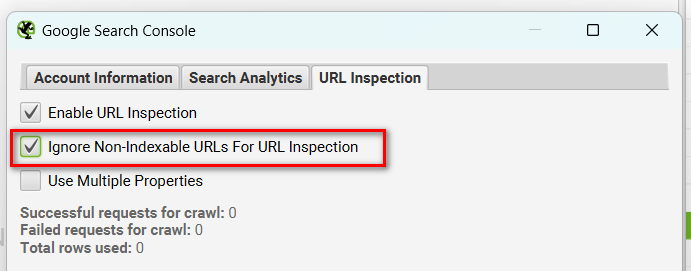
この方法では本来インデックス対象のURLに絞ってデータを取得できます。
特定のページ群に絞ってクロールする
Screaming Frogのクロール設定によってはクロール対象URLを絞ることができます。
例えば、特定のサブドメインのみクロールしたい場合は、クロールを開始する際にそのサブドメインをクロール起点として入力すればその配下のURLのみクロールされます。
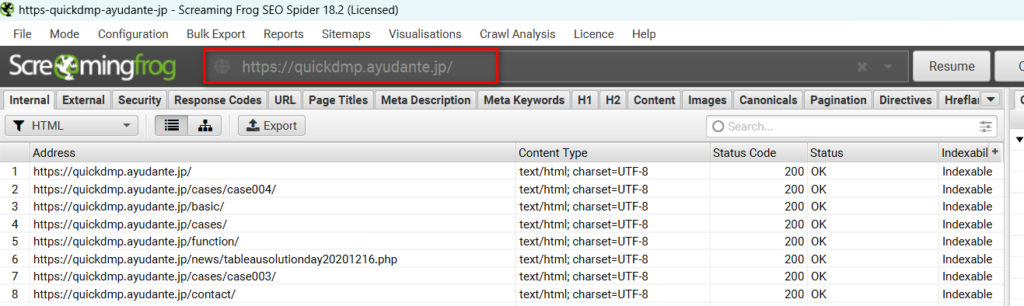
また、特定のサブディレクトリのみクロールしたい場合は、そのサブディレクトリをクロール起点として入力し、更に「Configuration」>「Spider」よりサブディレクトリ以外のURLをクロールするための設定である「Check Links Outside of Start Folder」からチェックを外します。このチェックを外せば、入力したサブフォルダ配下のURLのみがクロールされていきます。
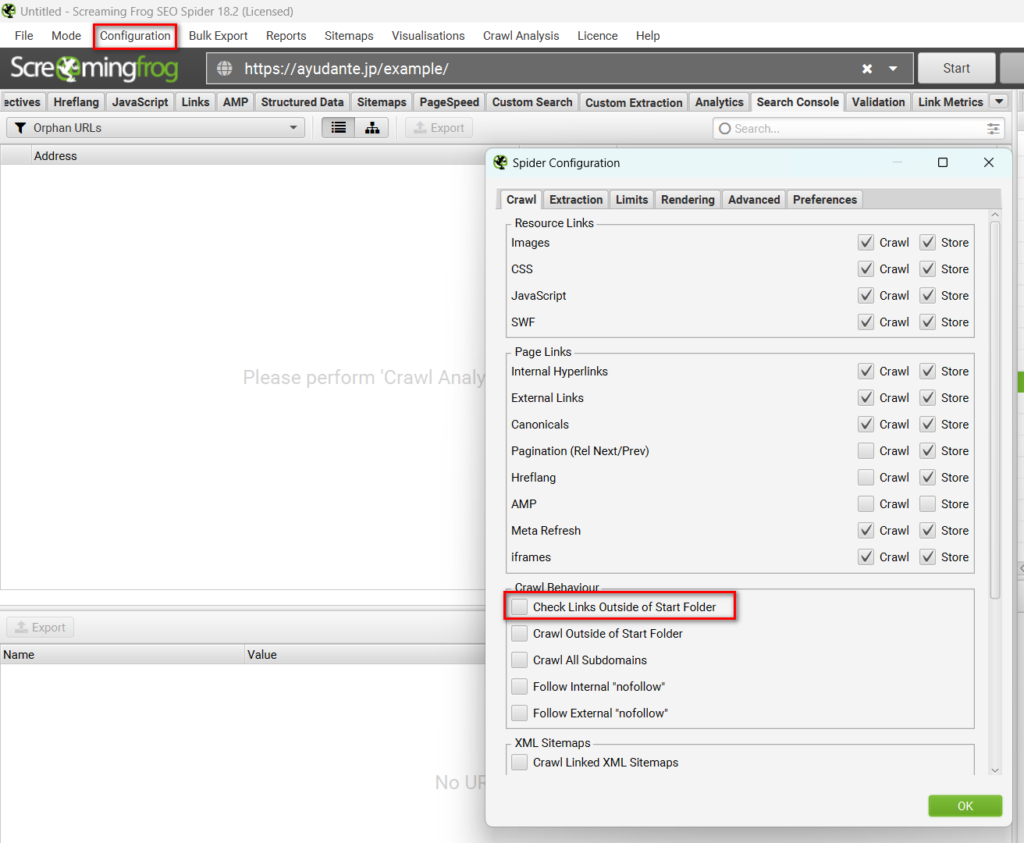
※サブディレクトリが「/」で終わらない場合、この設定を適用できず、次に紹介する「Include」での設定が必要となります。
更に、「Configuration」から正規表現を活用してより柔軟に特定のページ群に絞る(「Include」)もしくはデータが不要なページ群を除外する(「Exclude」)設定ができます。
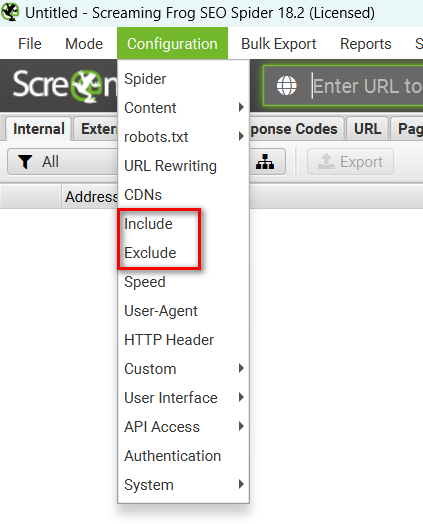
クロール対象URLをアップロードする
Screaming Frogのデフォルト設定ではクロール起点を入力し、Screaming FrogがそのURLからリンクされているURLを辿っていきますが、URL一覧をアップロードすることで、そのURLをピンポイントでクロールさせることもできます。
そのためには、「Mode」メニューから「List」を選びクロールモードを変更し、「Upload」ボタンをクリックし、URL一覧のファイルをアップロードする、URLを手入力もしくはペーストする、またはSitemap.xmlをURL一覧として活用することができます。
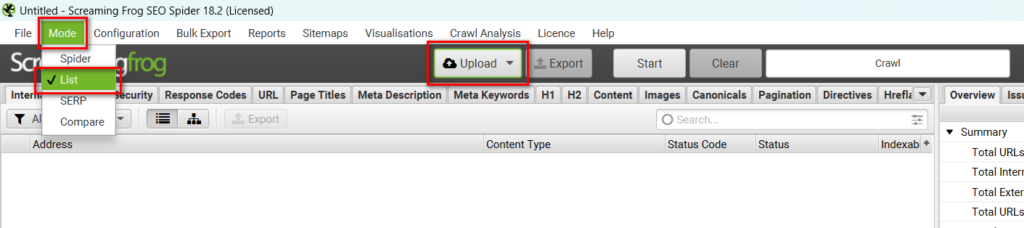
データを取得するURL数を増やす
大規模サイトでは短期間ですべてのURL Inspection APIの URLデータを簡単に取得する方法はありませんが、データが取得されるURL数をある程度増やすいくつかの工夫を紹介します。
1日待って、2001件以降のURLを再クロールする
クロール後24時間が経てば、再度2000件のURLのデータを取得できるようになります。2001件目のURL以降のURLを選択し、マウスの右クリックで表示されるメニューから「Re-Spider」をクリックすることでそのURLのデータを取得することができます。
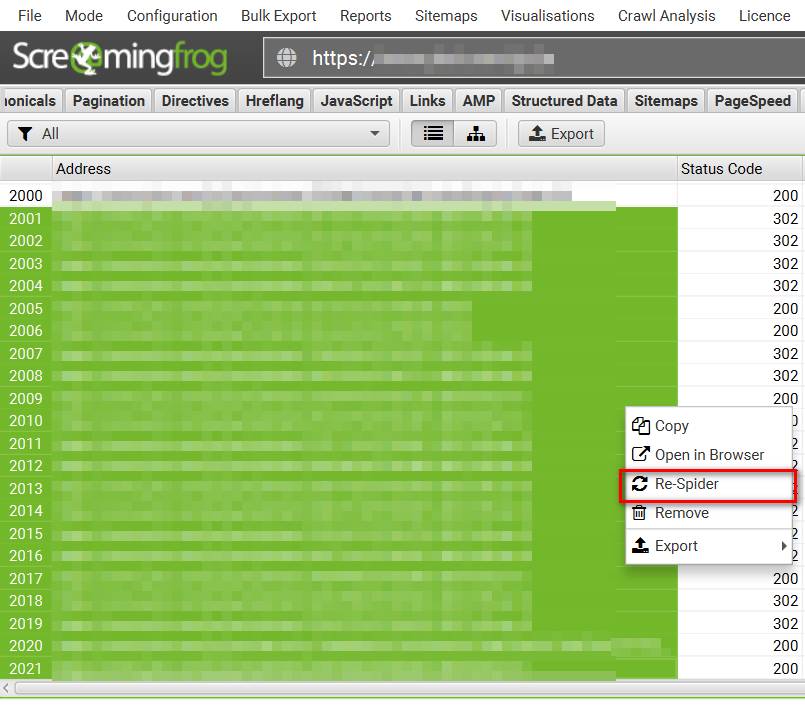
もしくは、そのURLをコピーし、先程紹介した「List」モードでアップロードしても良いです。
※Screaming Frogを起動するたびに、APIの連携を忘れずに設定しましょう。
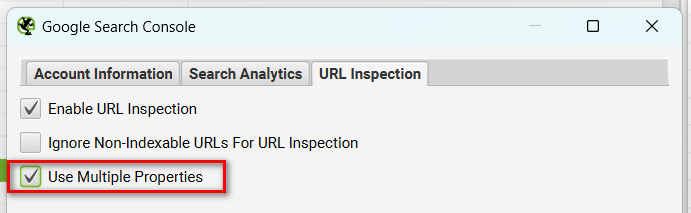
複数のプロパティと連携を行う
APIの制限がSearch Consoleプロパティ単位になりますので、もしサブドメインやサブディレクトリごとに複数のプロパティがある場合には、連携時の「URL Inspection」タブで「Use Multiple Properties」にチェックを入れれば、Screaming Frogが複数のプロパティでリクエストを分散するので、データ取得できるURL数が最大化されます。
特にページ群別にインデックス率や最後のクロール日を比較したい場合などに複数プロパティの活用が便利でしょう。
以上、Screaming FrogとSearch ConsoleのURL Inspection APIとの連携の紹介でした。
他にScreaming Frogの活用で気になるテーマがあれば、ぜひコガンのTwitterからリクエストください。テーマによっては取り上げて紹介させていただきます。











