今日のデータドリブンの世界では、膨大な量のデータを効率的かつスケーラブルに管理・変換し、企業が実用的なインサイトを得ることが極めて重要です。クラウドベースのソリューションへの依存度が高まる中では、合理的なデータパイプラインの必要性が高まっています。Google CloudのDataformは、BigQueryでSQLベースのワークフローを管理するための構造化されたフレームワークを提供し、このような状況の中で強力なツールとして登場しました。
ローデータの取り込みと最終的な分析/BIレポートの中間に位置するDataformは、データ変換の複雑さを簡素化し、正確性、拡張性、データチーム間のコラボレーションを保証します。本ブログでは、Dataformがデータパイプラインとして、どのような課題を解決しようとしているのかをご紹介します。
1. なぜDataformを利用するのか?
2. はじめに:セットアップと実装
2.1 リポジトリの作成
2.2 ワークスペースの作成
2.3 データソースの宣言
2.4 データ変換の定義 (BQテーブル/ビューの作成)
2.5 データ変換の実行
2.6 完了とコミット
3. まとめ
1. なぜDataformを利用するのか?
データパイプラインを扱う際にDataformを利用する主な理由は以下の通りです。
複雑なSQLスクリプトの管理:データパイプラインが大きくなると、SQLスクリプトの管理が難しくなり、潜在的なエラーや非効率につながります。DataformはSQLワークフローをモジュール化されたSQLXファイルにまとめることで、複雑な変換の管理、更新、拡張を容易にしています。
データジョブ間の依存関係のオーケストレーション:依存関係を手動で管理すると、エラーや不完全なデータ処理につながる可能性があります。Dataformは、ユーザーがSQLXファイル間の依存関係を明示的に定義することで、依存関係の管理を自動化し、スムーズで正確な実行順序を保証します。変換ステップのデータリネージはグラフィカルに表示できます:

データ品質の確保:大規模なデータセットでは一貫したデータ品質を確保することは難しく、手作業によるエラーが発生しがちです。Dataformはワークフロー内に組み込みテストを統合して、データ検証を自動化するので、変換プロセス全体を通して高品質なデータを確保します。
バージョン管理とコラボレーション:SQLスクリプトのコラボレーションは、適切なバージョン管理を行わないとコンフリクトや不整合を引き起こしかねません。DataformはGitとの統合により、シームレスなバージョン追跡、コラボレーション、ロールバック機能を実現し、安定性とチームの効率性を確保します。
2. はじめに:セットアップと実装
初期設定から最終的なデプロイまでスムーズに実装できるよう、各プロセスに分けて説明します。
2.1 リポジトリの作成:
Dataformをセットアップする最初のステップはリポジトリの作成です。このリポジトリはDataformプロジェクトのバージョン管理システムとして機能し、変更点の追跡、チームメンバーとの共同作業、データ変換コードの異なるバージョンの管理を可能にします。
Dataformのページ https://console.cloud.google.com/bigquery/dataform (プロジェクトでDataform APIを有効にする必要があります) → CREATE REPOSITORYをクリック
Repository IDとRegionを入力し、CREATEをクリック
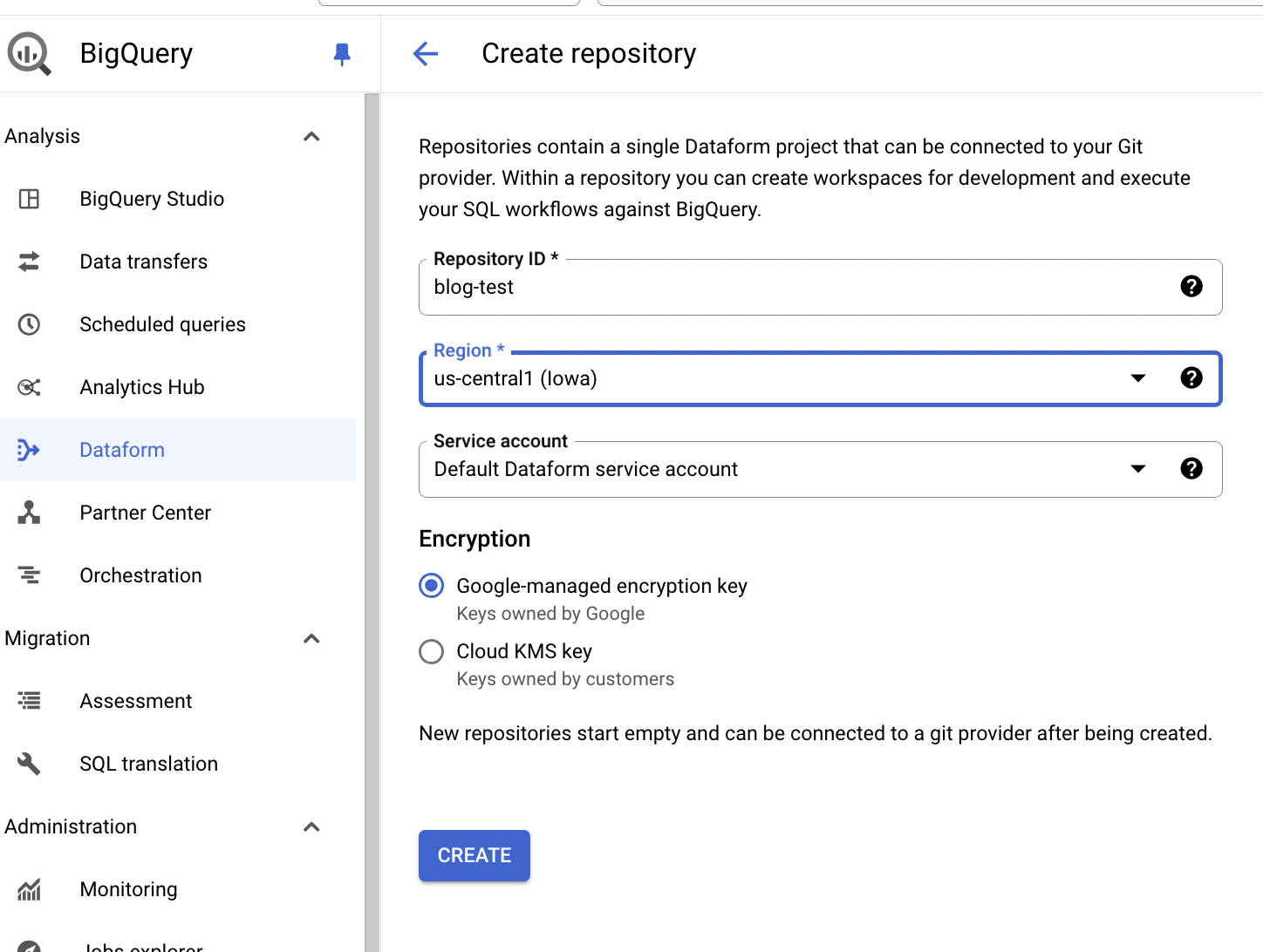
デフォルトのリポジトリはGoogle Cloud内に保存されバージョン管理されます。リポジトリをリモートのgitリポジトリ(GitHub、GitLab、Bitbucketなど)と連携させることも可能ですが、今回はデフォルト設定を元に説明します。
2.2 ワークスペースの作成:
Dataformのワークスペースは、プロジェクトの構造を定義しSQLスクリプトを整理する場所です。ここでデータパイプラインの様々なコンポーネントを論理的に作成します。
前のステップで作成したリポジトリに移動 → CREATE DEVELOPMENT WORKSPACEをクリック
Workspace ID を入力し、CREATE をクリック
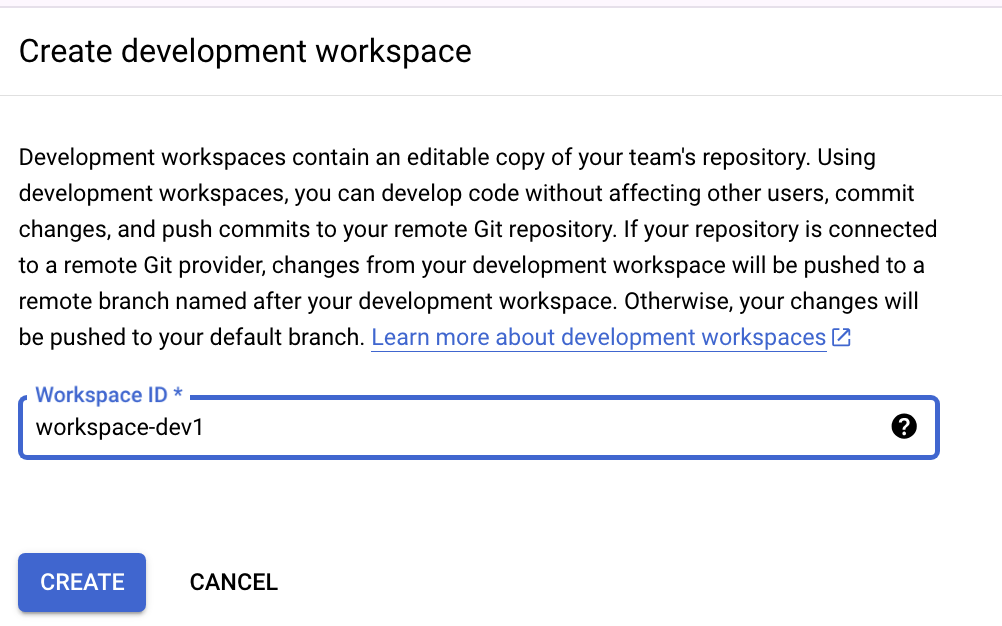
ワークスペースが作成された後の画面 → INITIALIZE WORKSPACEをクリック
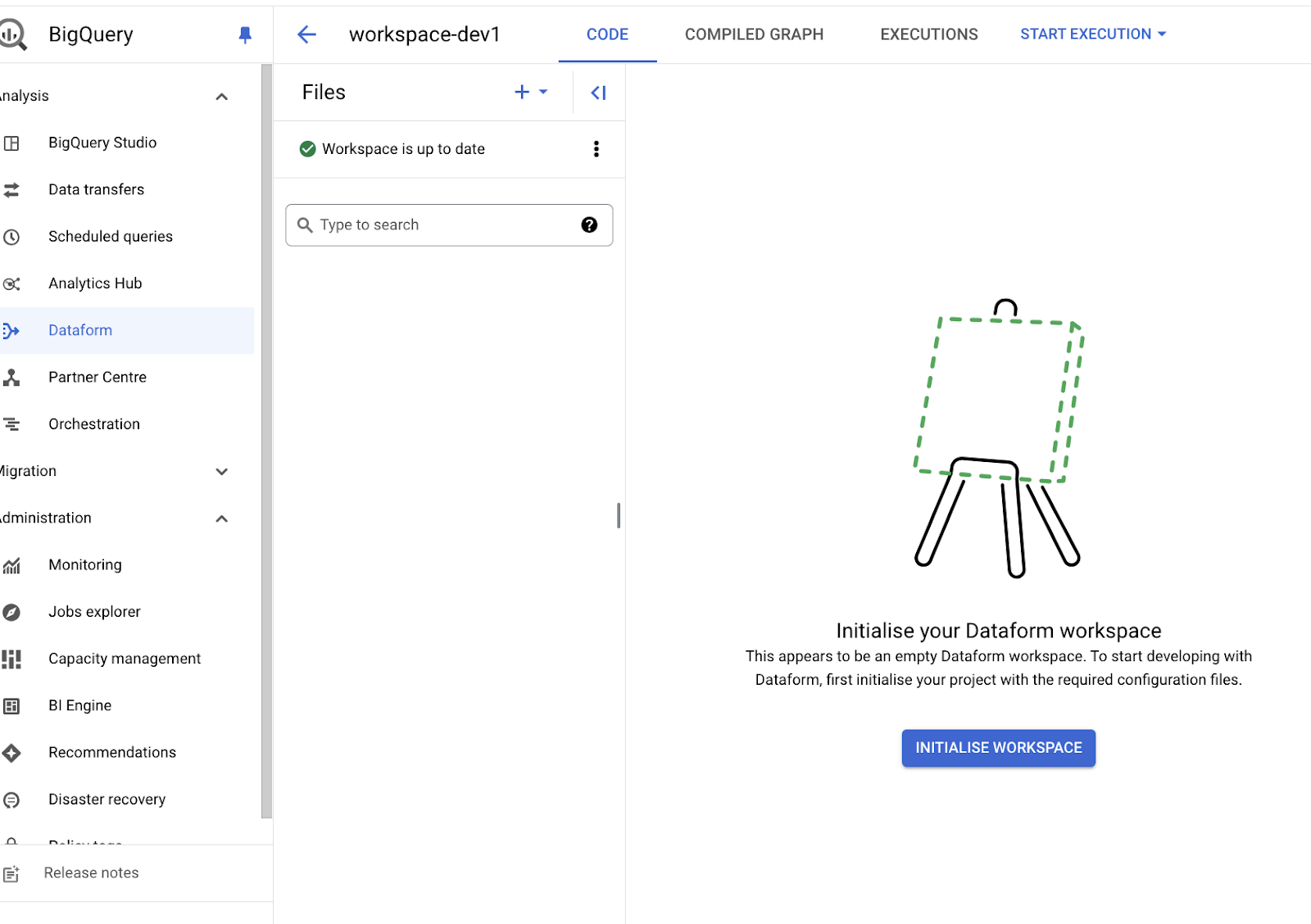
新しいワークスペースが初期化されると、このように表示されます。
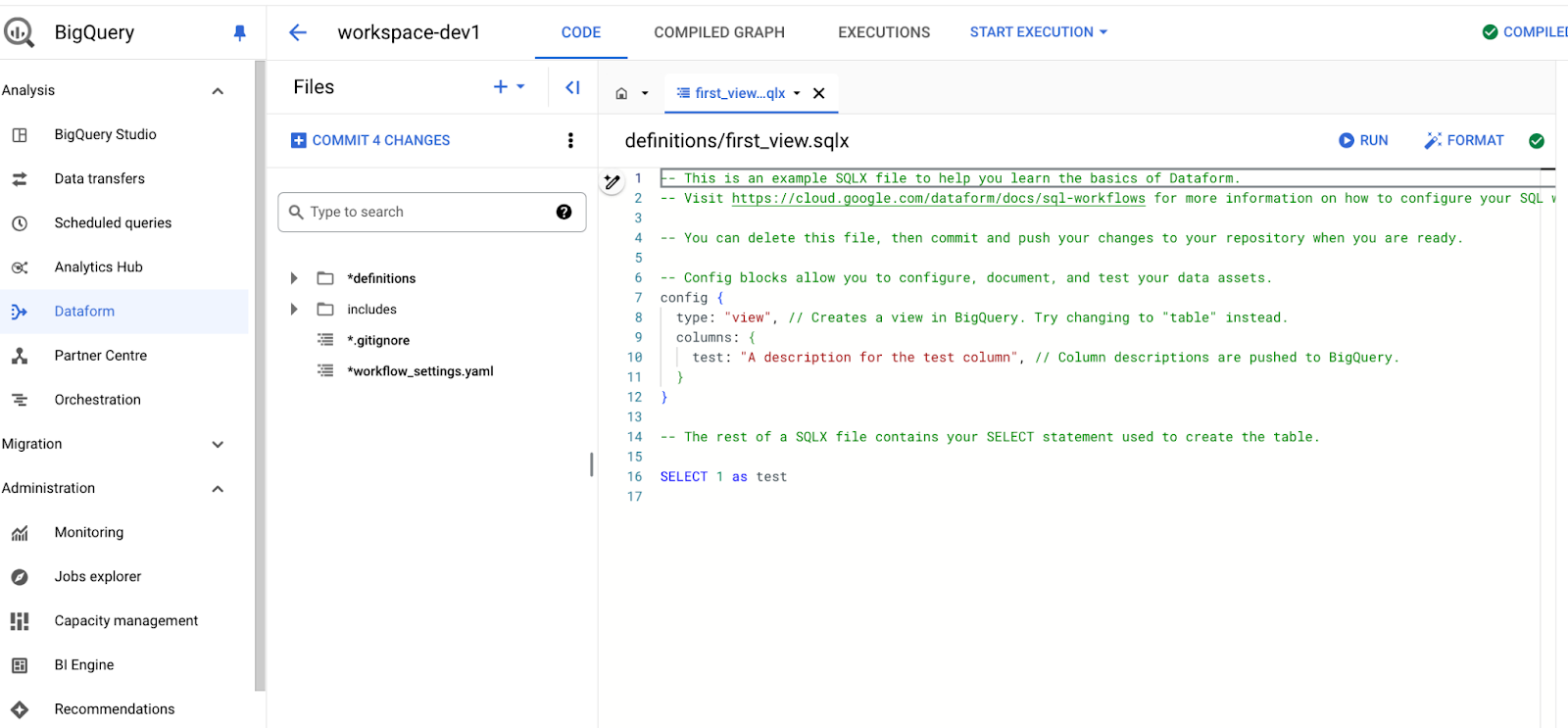
Dataformのワークスペースの主なコンポーネントは以下のとおりです。
- workflow_settings.yaml ファイル: Dataformプロジェクトの主要な設定ファイルです。BigQueryプロジェクトIDやデフォルトのデータセットのロケーションなど、プロジェクト全体に適用されるグローバルな設定を含みます。
- definitions ディレクトリ: 変換ロジックの核となる部分です。パイプラインで使用する変換、テーブル、ビュー、宣言を定義するすべての SQLX ファイルを格納します。
開発を始めたら、ビジネス要件に合わせてファイルやディレクトリを増やすことができます。ワークスペースを効率的に整理するために、定義(SQLXファイル)、インクルード(一般的なSQL関数)、テスト(データ品質チェック)などのディレクトリを作成して、複雑な変換を体系的に効率的に管理していきます。
2.3 データソースの宣言:
データソースとは、変換の対象となるローデータテーブルやデータセットのことです。データソースは、様々なシステムからのローデータを格納するBigQueryのテーブルである必要があります。
definitions ディレクトリ内 → データソースを宣言する新しいSQLXファイルを作成。作成したSQLXファイルへ、例えば以下のコードをコピーして貼り付けます。
config {
type: "declaration",
database: "my_project_id",
schema: "my_dataset",
name: "my_table_name"
}BigQueryプロジェクト内のデータソーステーブルの正確な場所を指定します。このコードにより、Dataformが変換の対象となるローデータテーブルを認識するようになります。
参照: https://cloud.google.com/dataform/docs/declare-source
2.4 データ変換の定義 (BQテーブル/ビューの作成):
Dataformのデータ変換は、ソース(ローデータ)を処理し、分析に適した構造化形式に調整するSQLスクリプトです。これらの変換結果でBigQueryの新しいテーブルやビューが作成されます。
definitions ディレクトリ内 → transformed_table.sqlxというSQLXファイルを作成。データ変換のSQL記述し、最初の変換ステップを定義
例えば、以下のコードをコピーして貼り付けます。
— transformed_table.sqlx
-- transformed_table.sqlx
config { type: "table" }
SELECT
order_date AS date,
order_id AS order_id,
order_status AS order_status,
SUM(item_count) AS item_count,
SUM(amount) AS revenue
FROM ${ref("source_table_name")}
GROUP BY 1, 2configブロックのtypeフィールドには出力をテーブルにするかビューにするかを指定します。configブロックは、出力タイプの他、パーティショニング、クラスタリング、テーブルの説明など、テーブルの様々なプロパティを定義することもできます。
デフォルトでは、BQのテーブル/ビュー名はSQLXファイル名と同じになります。例えば、transformed_table.sqlxファイルの変換結果のテーブルはBQでtransformed_tableとして保存され、${ref(“transformed_table”)} として下流の変換ステップで参照することができます。
別の新しい SQLX ファイルを追加し、その新しいファイルから${ref(‘transformed_table’)}として参照することで、変換ステップを追加できます。変換ステップの依存関係の定義は正しい順序で実行されることを保証します。
参照: https://cloud.google.com/dataform/docs/define-table
この段階でCOMPILED GRAPHに移動すると、変換ステップの完全なデータリネージを見ることができます。
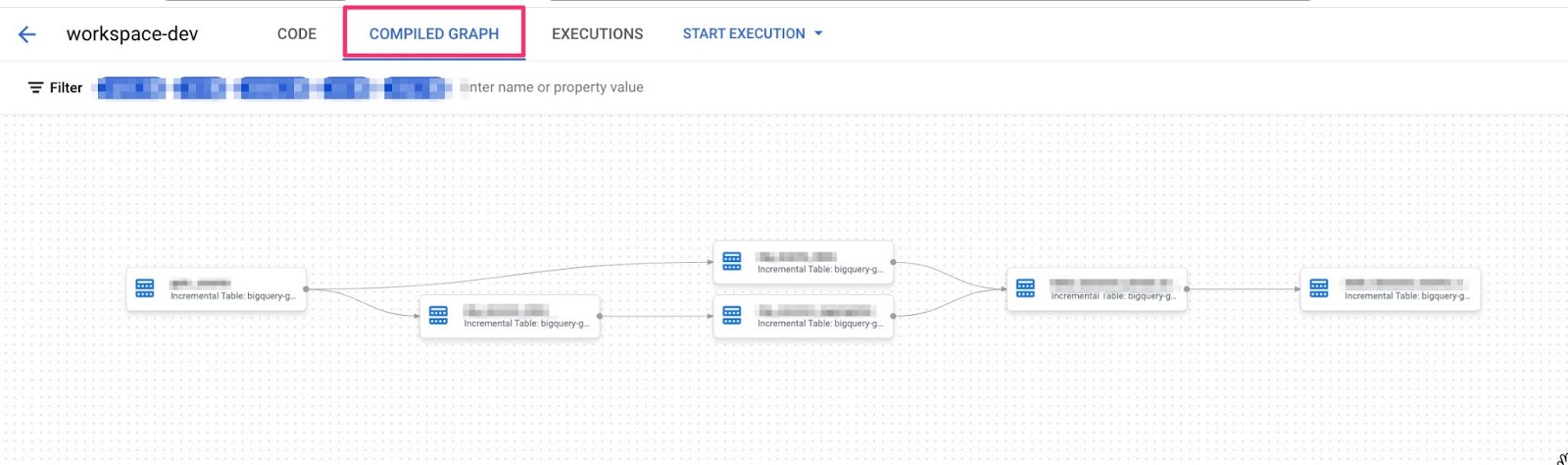
2.5 データ変換の実行:
Dataformでリポジトリ、ワークスペースを設定し、データソースを宣言し、データ変換を定義したら、次はデータ変換を実行します。このプロセスではパイプラインを実行し、作成したすべてのSQLXファイルが設定した依存関係の順に処理され、結果のテーブルまたはビューをBigQueryに作成します。
パイプラインを実行する際、Dataformはdefinitions ディレクトリ内の全てのSQLXファイルを読み込み、これらのファイル間で定義した依存関係に基づいて実行順序を決定し、他のテーブルやビューに依存するデータ変換は、その依存関係が正常に完了した後に処理されるようにします。この依存関係の管理が、実行の順序、最終データの正確性と完全性に影響を与えるため、複雑なパイプラインでは非常に重要です。
Dataformでデータ変換を実行する場合、手動実行と自動実行の2つの方法があります。
本ブログでは説明の簡略化のため、主に開発段階や単発の実行で使用される手動実行についてのみ説明します。
運用フェーズでは、自動実行(スケジュールされた実行など)を利用することになるため、パイプラインを定期的に実行するための間隔(毎日、毎週など)を設定します。自動実行については、次回のブログ(「ワークフロー設定」、「ワークフローとCloud Scheduler」、「Cloud Composer」)で取り上げる予定です。ただ、もし先に興味があるようだったら、Google Cloudのドキュメント https://cloud.google.com/dataform/docs/workflow-configurations を参照ください。
Dataformは、データ変換の実行を手動で開始できるユーザーフレンドリーなインターフェースを提供しています。この操作は簡単でコマンドラインの知識も必要ないため、CLIツールにあまり慣れていないチームメンバーでも利用できます。
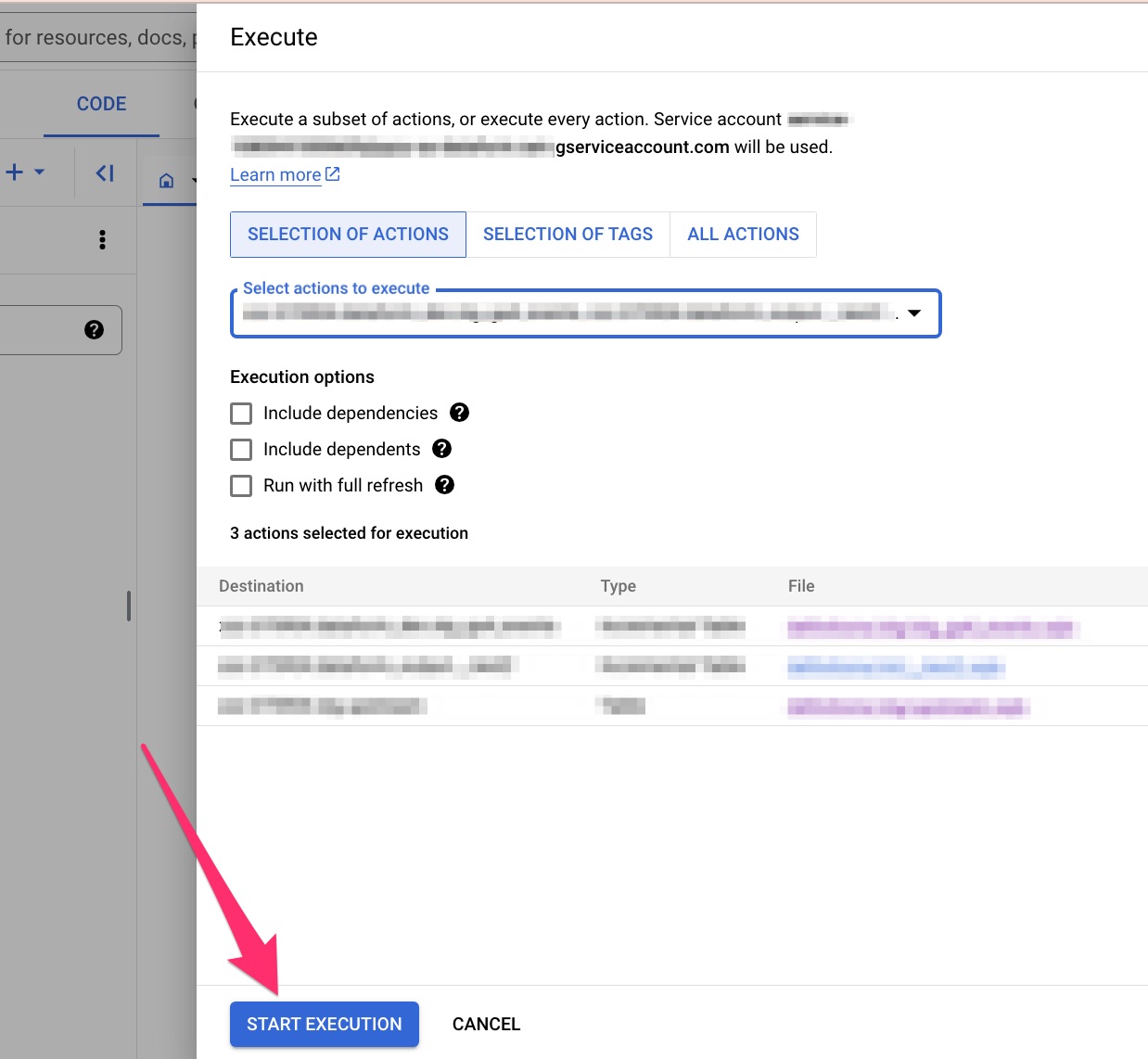
メインのダッシュボード(リポジトリ → ワークスペース)で、START EXECUTION ボタンを見つける
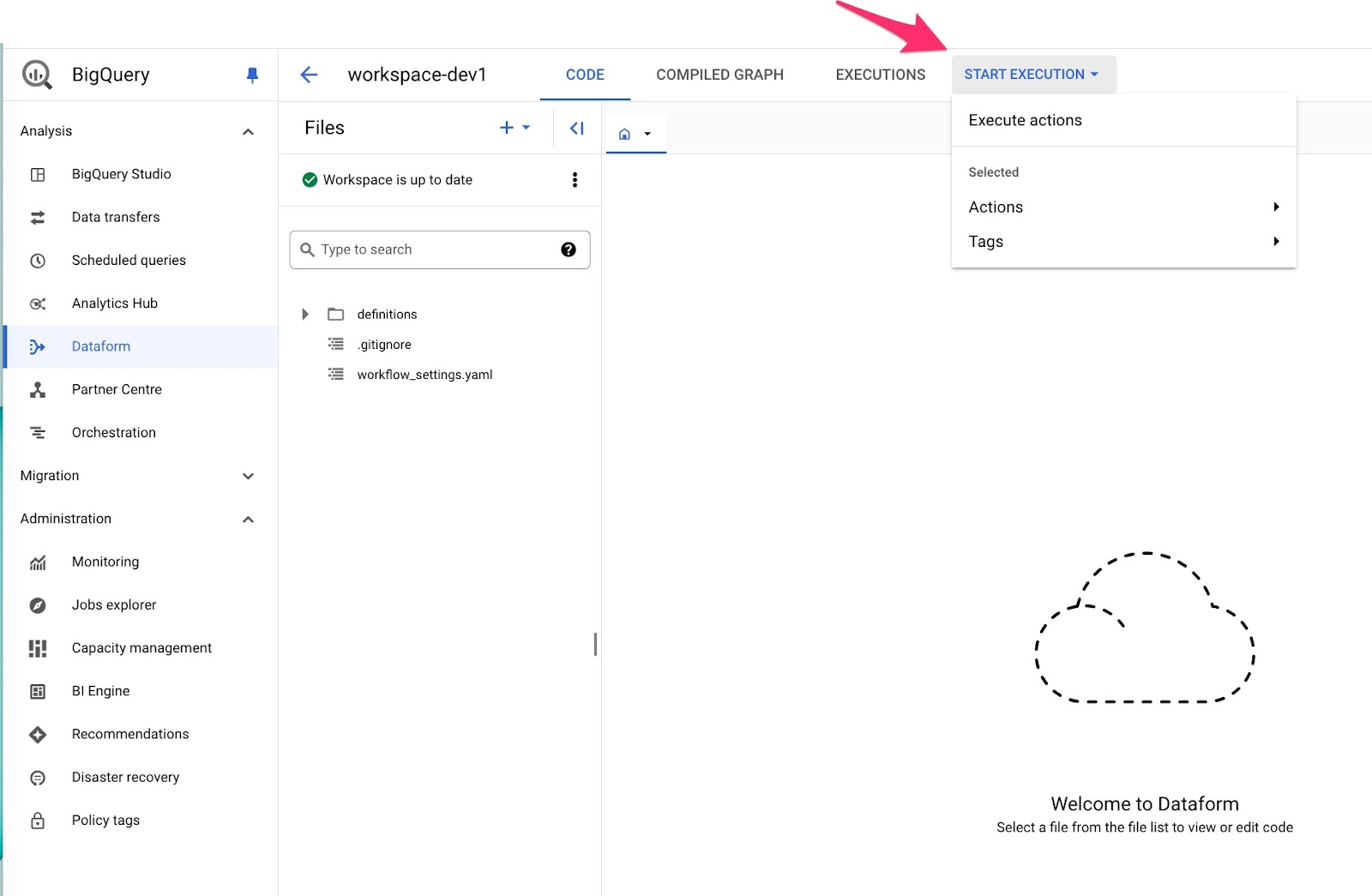
Execute actions をクリックすると、いくつかのオプションが表示され、次の処理が実行できます:
- すべての変換 SQLX ファイルを実行するのではなく、変換 SQLX ファイル (アクション) のサブセットのみを選択して実行します。たとえば、下流のロジックのデータ変換だけを実行し、上流のデータ変換を実行させないということも可能です。
- テーブルのフルリフレッシュ、またはインクリメンタル処理などの実行を選択します。インクリメンタルテーブル設定は少し高度なトピックなので後回しにしますが、今はチェックを外しておいてください(チェックを入れても、現時点でのユースケースでは出力に違いは生じません)。このチェックはインクリメンタルテーブル設定する時に必要な設定です。
参照: https://cloud.google.com/dataform/docs/incremental-tables
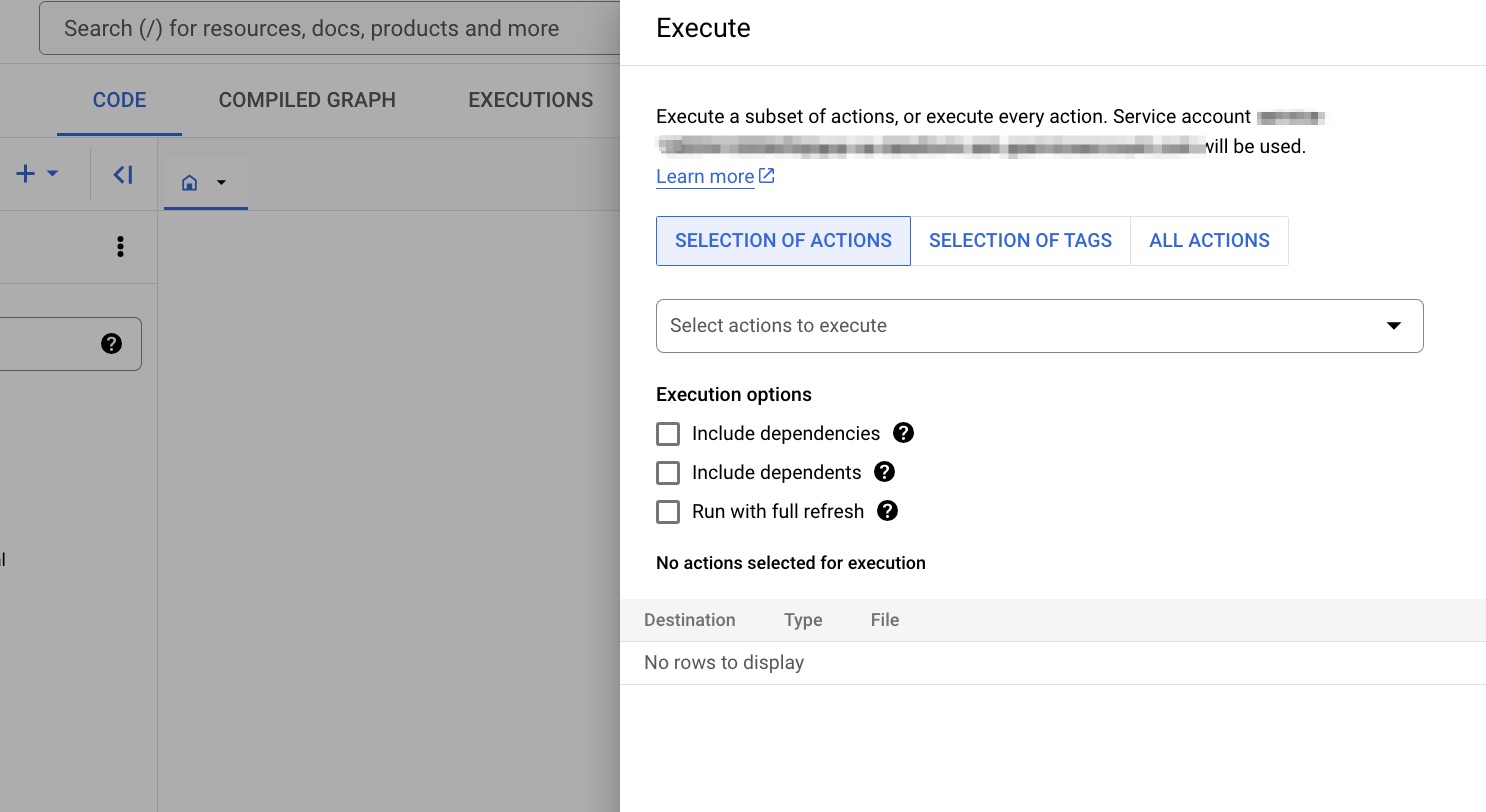
最終的な選択が終わったら、一番下にあるSTART EXECUTIONボタンをクリック
処理の実行後、データ変換が期待通りの結果をもたらしたかどうかを検証することが重要です。そのため、BigQueryで新しいテーブルやビューが作成されていること、作成されたテーブルやビューが正しくなっているかを確認します。
デフォルトでは、インクリメンタルテーブルが設定されていない限り、Dataformは実行ごとにテーブルやビューを再作成します。インクリメンタルテーブル設定は新しいデータをテーブルに挿入してテーブルを更新します。インクリメンタルテーブル設定の前に述べたように、少し高度なトピックとなるのでGoogle Cloudのドキュメント https://cloud.google.com/dataform/docs/incremental-tables を参照ください。
2.6 完了とコミット:
データ変換がうまくいったならば、いよいよ作業を完了させます。これは変更をリポジトリにコミットし、リモートのバージョン管理システムにプッシュする作業となります。
メインのダッシュボード(リポジトリ → ワークスペース)で、COMMIT 1 CHANGE リンクを見つける(前回のコミット以降に行った変更の数に応じて、2 CHANGES、3 CHANGESなどになります)
このリンクをクリックすると、この画面が表示されます。
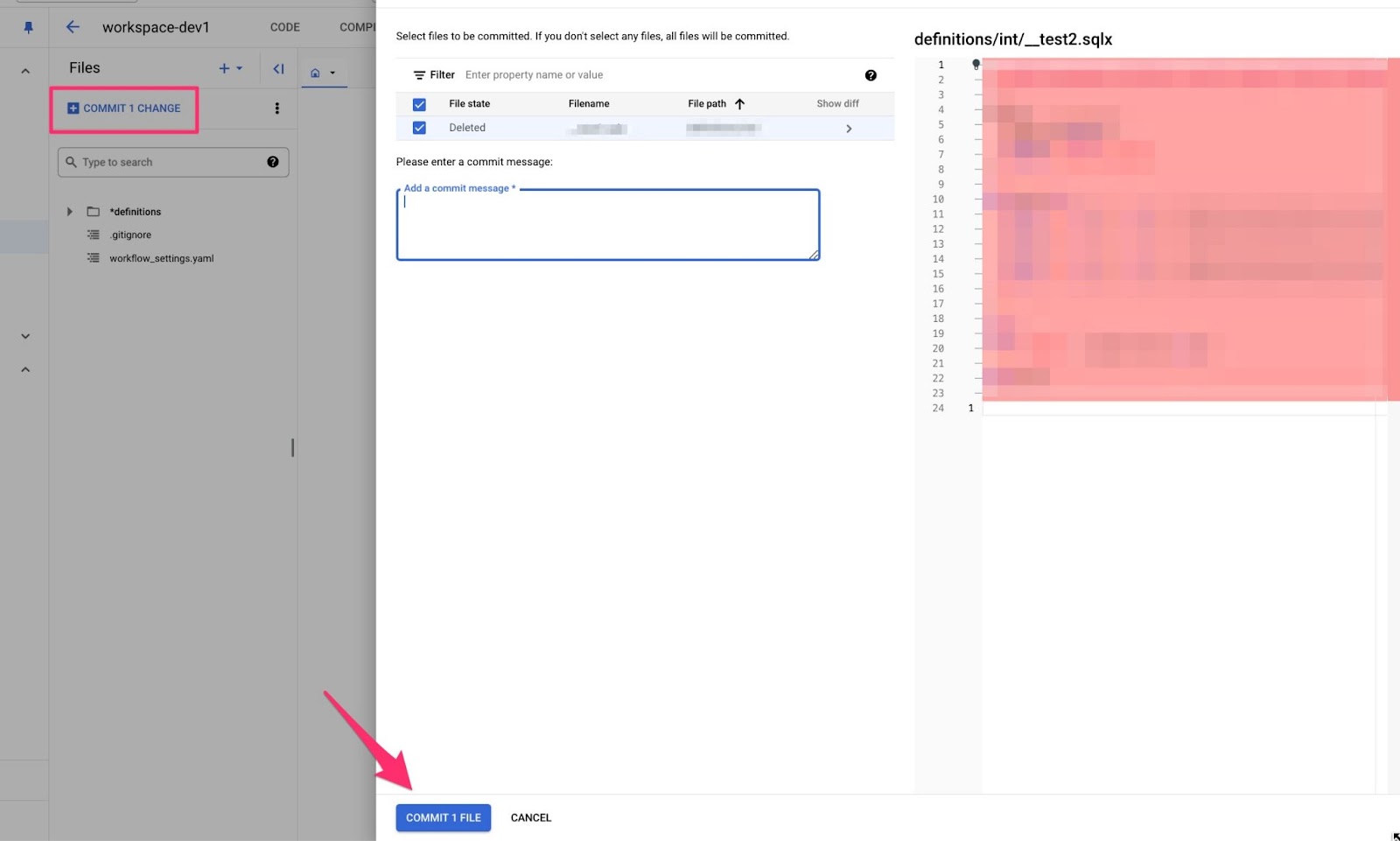
前回のコミット以降に変更されたすべてのファイルと、あなたが行った変更が表示されます。コミットメッセージを書き、一番下の COMMIT 1 FILE をクリック(前回のコミット以降に行った変更の数に応じて、2 FILES、3 FILESなどになります)
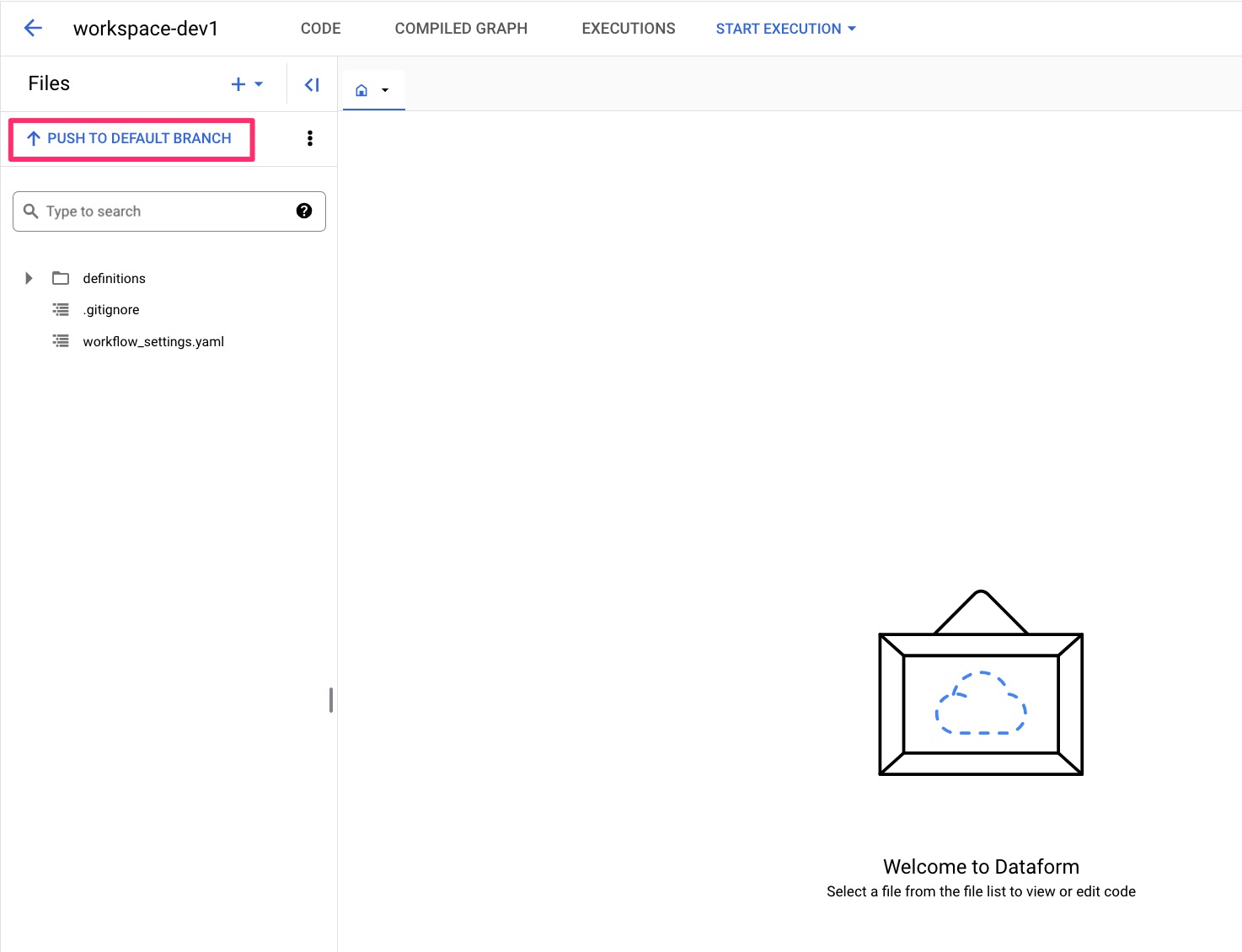
すべてのコミットが完了して、 PUSH TO DEFAULT BRANCH をクリックすると、ワークスペースが新しい変更で最新の状態になります。
3. まとめ
Dataformの設定と実装に関するこのステップバイステップガイドは、Google Cloudでデータ変換を始めるための明確なロードマップとなるはずです。これらの構造化されたステップに従うことで、データパイプラインを効率的に構築、管理、拡張することができます。「リモートgitリポジトリ」、「インクリメンタルテーブルの設定」、「自動実行(またはスケジュールされた実行/実行)」など今回触れられなかった高度なトピックもありますが、これらは本番環境で運用する時に必要となるため、近いうちにカバーしたいと考えています。