If you linked your GA4 property to BigQuery, use daily export data to feed into daily reports, or use it for actionable marketing automation use cases, one problem you may be experiencing is – how to know the exact timing of the full stable export of previous day’s traffic data (table named events_YYYYMMDD from the previous day) and when to trigger downstream job to begin querying this data. Daily export does not arrive at a fixed time and the linking lacks any such notification mechanism.
Problem we’re trying to Solve
Every time the GA4 export is delayed, your downstream job will fail. Triggering a chain of emails to helpdesk, google support, lost man hours, distraction etc. and unpredictable wait to recover the data that hasn’t arrived in BigQuery yet!
Some strategies (rather tactics) that can mitigate the pain:
- Delay triggering a downstream job by some “x” hours, with a strong assumption that export will arrived by this delayed timeline
- but further delaying your access to fresh data if export arrives earlier than expected; or what if export is unexpectedly delayed by as long as a day or two ?!
- OR, keep checking at regular intervals whether export has arrived (for ex. pinging in for the existence of <events_YYYYMMDD> table before triggering downstream jobs
- again, delaying your access to data and adding further complexity to your data pipelines
Both these tactics may reduce the failure rate, improve predictably but none still completely eliminates the unpredictability of export timing. And with GA4 export we have seen that it can be highly unpredictable
- Sometimes export may arrive next day early morning 7/8am and sometimes past mid-day or even late evening 6/7pm or a day later
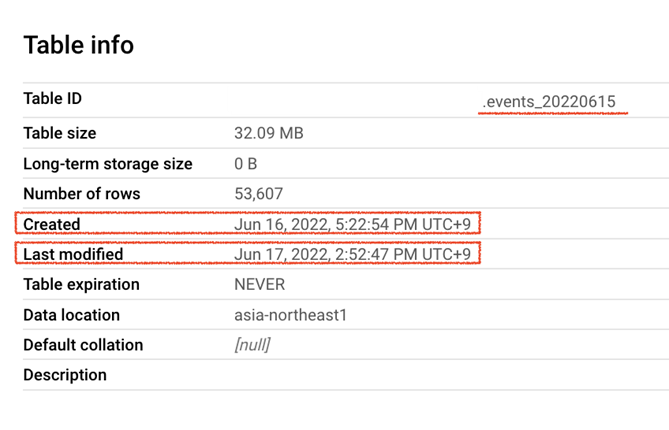
- Additionally, export for a specific date may happen multiple times (not in a single shot) because in GA4, events are processed if they arrive up to 72 hours late (so called “late-hits”). As you can see export for events_20220615 first happened on June 16th (Created time) and then again on June 17th (Modified time)
Solution – Cloud Event Driven solution
In this article we propose a Cloud Event Driven solution for GA4 BigQuery export notification to address this issue. We also give a step-by-step guide to implement it entirely in Google Cloud Platform (GCP). We will be using the following GCP components:
Cloud Logging: Stores information about every event happening in your GCP Project in a structured logs format. Think about when you create BigQuery dataset / table, issue a query against the BigQuery table, or even add / remove users permissions to the project –all these cloud events and This is the place you should head to when you want to know what’s happening in your GCP project. As soon as our new GA4 export table arrives, this event is also logged in Cloud Logging. We’ll use this log entry to trigger our notification.
Pub/Sub: Scalable event ingestion messaging queue system. It consists of a Publisher Topic on one end (where event data is published) and a linked Subscriber(s) on the other end (independently listening to these events data). Through some custom code, Subscriber(s) can process this event data using desired business logic, as and when they are published.
Cloud Functions: Runs any custom code in the cloud serverless execution environment (currently supports Python / Go / Java / Node.js / PHP / Ruby) . You simply write your code for single-purpose, set a trigger when this code runs. Currently supported triggers are – HTTP request to functions’s endpoint, message published to Pub/Sub topic, file object created / modified / deleted from Cloud Storage, to name a few…
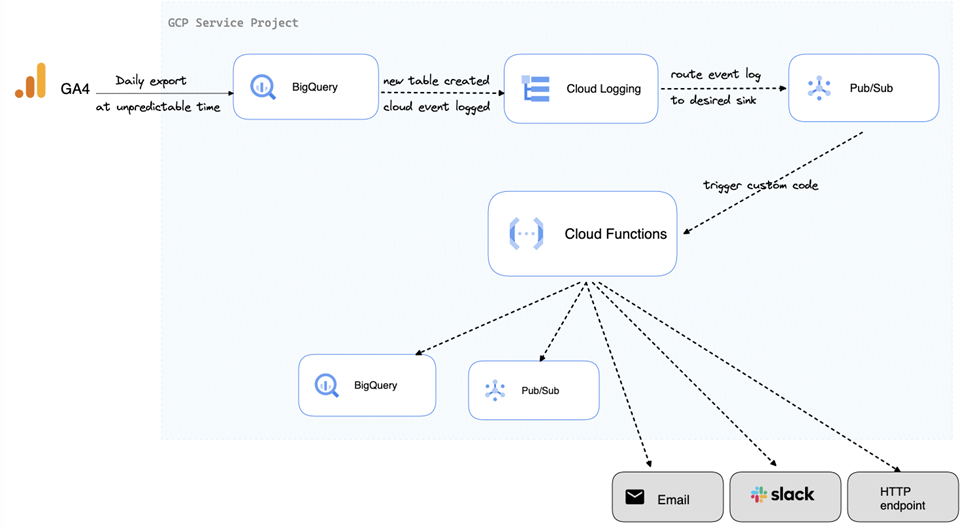
Architecture we use
Using these GCP components, the architecture for our export notification solution looks as follows:
Implementation guide
STEP1
Head to Log Explorer and copy / paste this query in the query box (if you don’t see the query box, switch ON the toggle “Show query” on right side)
resource.type="bigquery_resource"
protoPayload.authenticationInfo.principalEmail="firebase-measurement@system.gserviceaccount.com"
protoPayload.serviceData.jobCompletedEvent.eventName="load_job_completed"
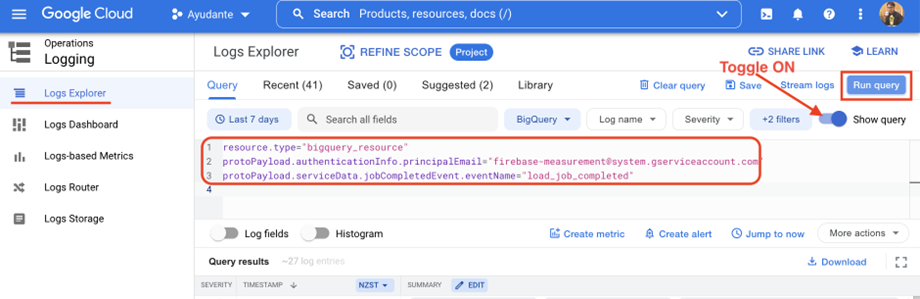
—> Hit “Run query” button on the right side
——————————————————————————————————-
UPDATE (2022.05.25): for new implementation, recommend to use a new BigQueryAuditMetadata version of logs, the above AuditData is old version of BigQuery logs. Accordingly, slightly adjust Cloud Functions code as well (see STEP3 below).
resource.type="bigquery_dataset"
protoPayload.authenticationInfo.principalEmail="firebase-measurement@system.gserviceaccount.com"
protoPayload.serviceName: "bigquery.googleapis.com"
protoPayload.methodName="google.cloud.bigquery.v2.JobService.InsertJob"
protoPayload.metadata.tableDataChange.reason="JOB"——————————————————————————————————–
This will display all the event logs from previous exports (If you don’t see any results, extend the date range to include the last few days for which exports have already completed)
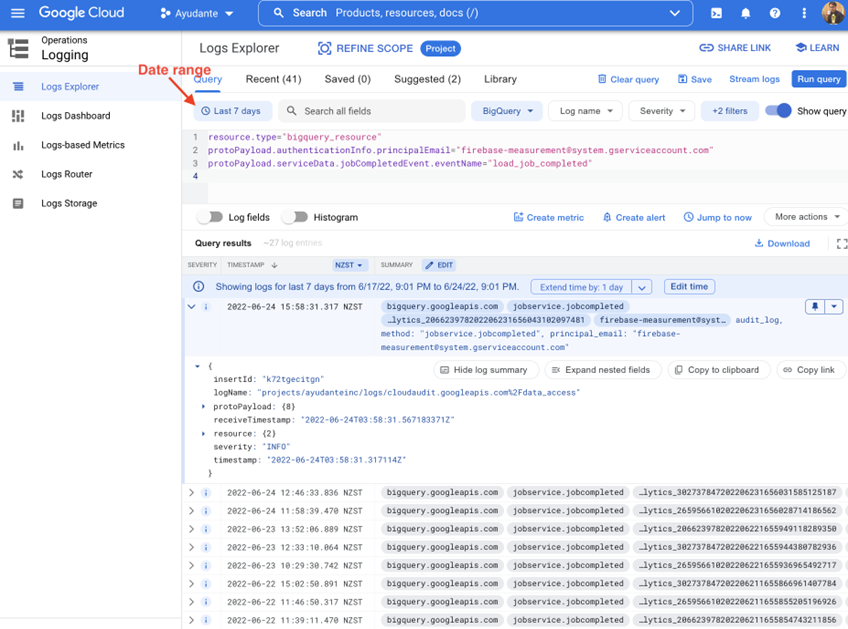
What we are doing here is, filtering cloud event logs to only those that relate to bigquery_resource and,
- initiated by a user firebase-measurement@system.gserviceaccount.com → you might recall, this is the service account email responsible for the GA4 daily export
- and relate to load_job_completed event → GA4 daily export is ingested into BigQuery as a Load Job. Completion of this job indicates, exports have arrived in BigQuery
Expand each log entry result to explore audit data associated with each daily export event for ex. Cloud Project ID, BigQuery Dataset ID, Table ID, exact export time etc. You can find a full list of keys in documentation – LogEntry, AuditLog & BigQuery AuditData. Utilize these fields to further filter your logs limiting to specific dataset ID for which you are interested in (equiv. to GA4 Property ID for our daily export notification purpose)
UPDATE (2022.05.25): for new implementation, recommend to use BigQueryAuditMetadata version of logs, the above AuditData is old version of BigQuery logs. Accordingly, alightly adjust Cloud Functions code as well (see STEP3 below)
STEP2
In this step we will set up a notification mechanism to notify a Pub/Sub topic as and when GA4 daily exports have arrived in BigQuery.
From the Log Explorer results screen (in STEP1) click “More action” drop down (or it might just say “action”) —> “Create Sink”.
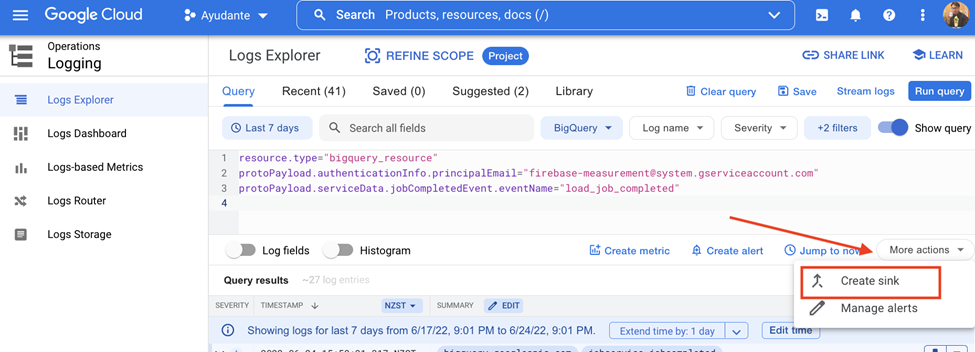
A new window (“Log Router” screen) opens.
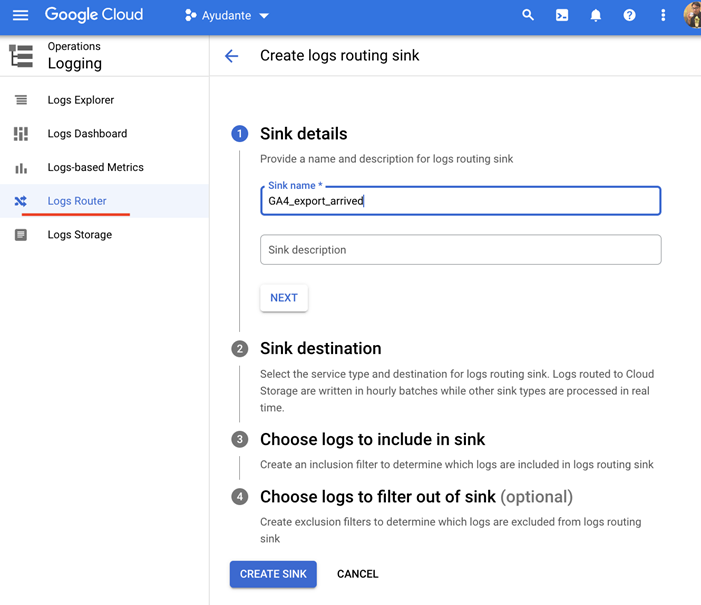
- Enter anything in the “Sink name” & “Sink description” fields (I have chosen GA4_export_arrived and left description blank).
- Click “Next”
Under “Sink destination”
- click “Select sink service” dropdown —> select “Cloud Pub/Sub topic”
- click “Select a Cloud Pub/Sub topic” dropdown → click “Create A Topic”
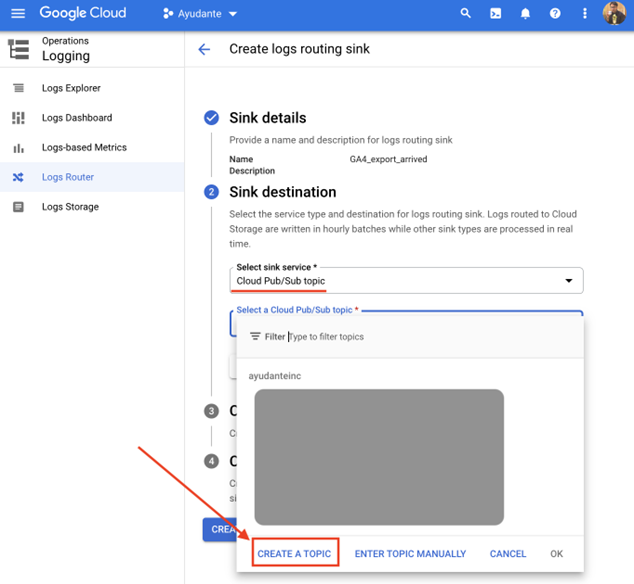
A new “Create a Topic” overlay screen will appear. Enter any “Topic ID” name you’d like (I’ve chosen ga4_exports_arrived), leave the rest of options as default and click “Create Topic” and then click “Create Sink”
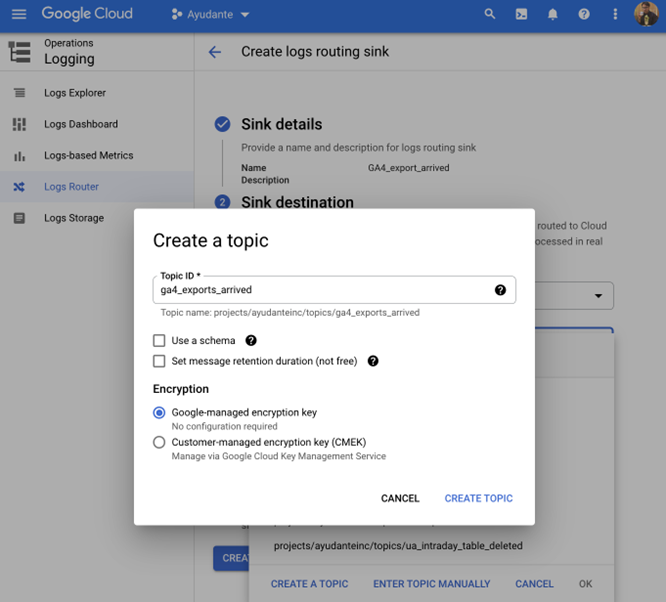
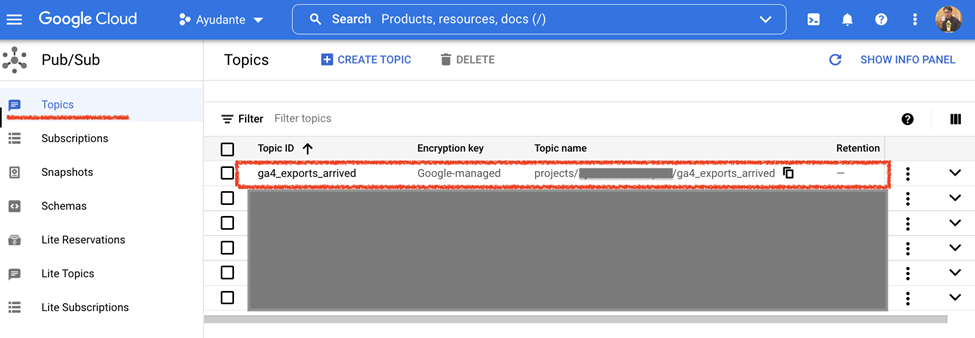
After all this is set up, if you head to Pub/Sub service within the cloud project, you’ll notice a new Publisher Topic that we just created. What we have done so far is – each time, as and when new daily export arrives, a notification will be sent to this Publisher Topic.
——————————————————————————————————-
UPDATE (2022.05.25): for cross project set up, when using a sink to route logs to different Cloud projects, additional set up is needed to grant neccessary permissions https://cloud.google.com/logging/docs/export/configure_export_v2#dest-auth
——————————————————————————————————–
STEP3
From here on, we will deploy a Cloud Function that listens to new messages published on Publisher Topic we created above and executes our custom code each time a new message is published.
Head to Cloud Functions and click “Create Functions”
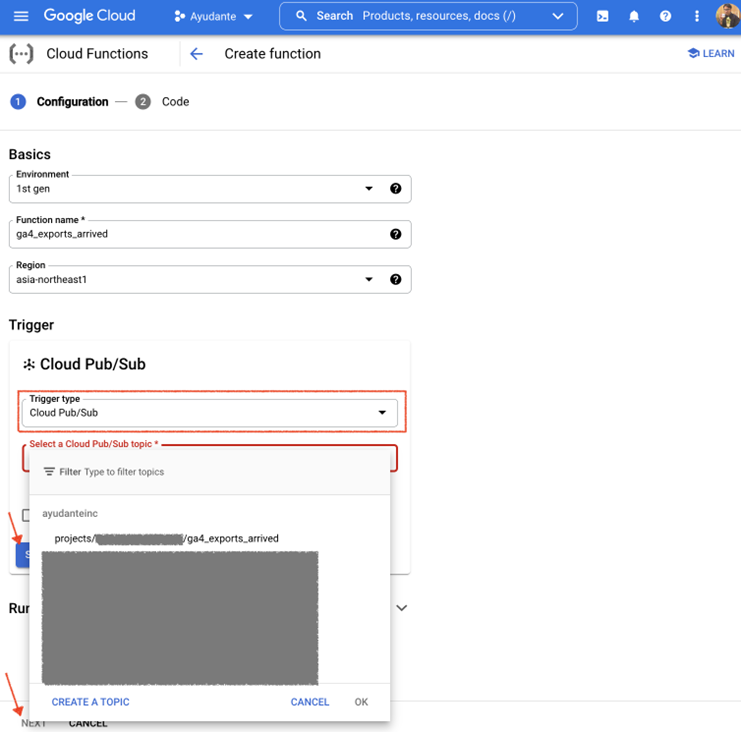
In the “1. Configuration” step that appears next:
- Enter anything you want in the “Function name” (I have chosen ga4_export_arrived).
- Choose the same “Region” as the Publisher Topic we created in the previous step (generally any region will work, unless Cloud project Organization policies have Resource Location Restriction organization policy). I have chosen asia-northeast1 (Tokyo)
- Under the Trigger sector, click “Trigger type” dropdown and select “Cloud Pub/Sub”
- Under “Select a Cloud Pub/Sub topic” dropdown, choose the Publisher Topic we created in the previous step.fdxw
—> Click “Save” button and then “Next”
You can configure other Cloud Function details if you are well familiar (for ex. Memory, timeout, autoscaling, Service Account etc.) , otherwise default options work just fine.
One work of caution on security – By default Cloud Function uses the automatically created Default App Engine Service Account email “PROJECT_ID@appspot.gserviceaccount.com” as its runtime identity. Although this is not recommended for production use, for our prototype purpose we will let it be without making further changes to default configurations.
In the next screen “2. Code” you will see like this
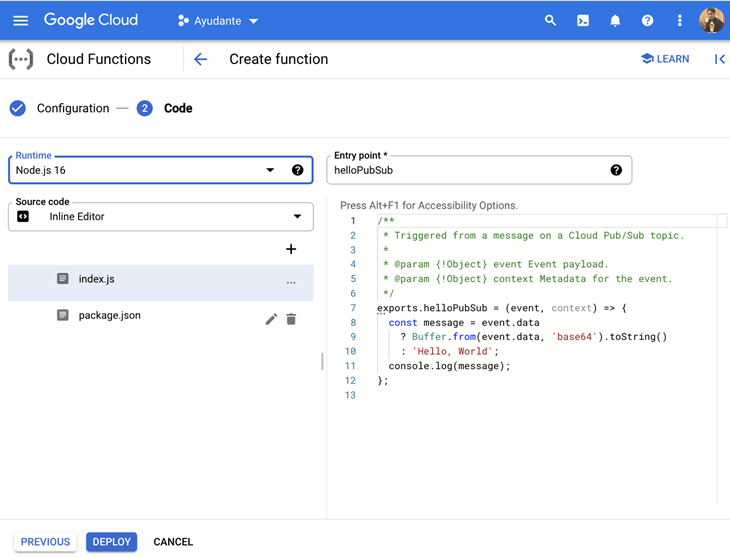
Under “Runtime“ dropdown, choose Python 3.9 (or the latest one available). You can choose any other runtime (Go / JAVA / Node.js / PHP / Ruby) for custom code that you are familiar with, I’ve chosen Python runtime.
In the “Entry point“ field, enter your function name. It can be anything, but must match the same as the function name in your custom code. In our case it’s ga4_export_arrived.
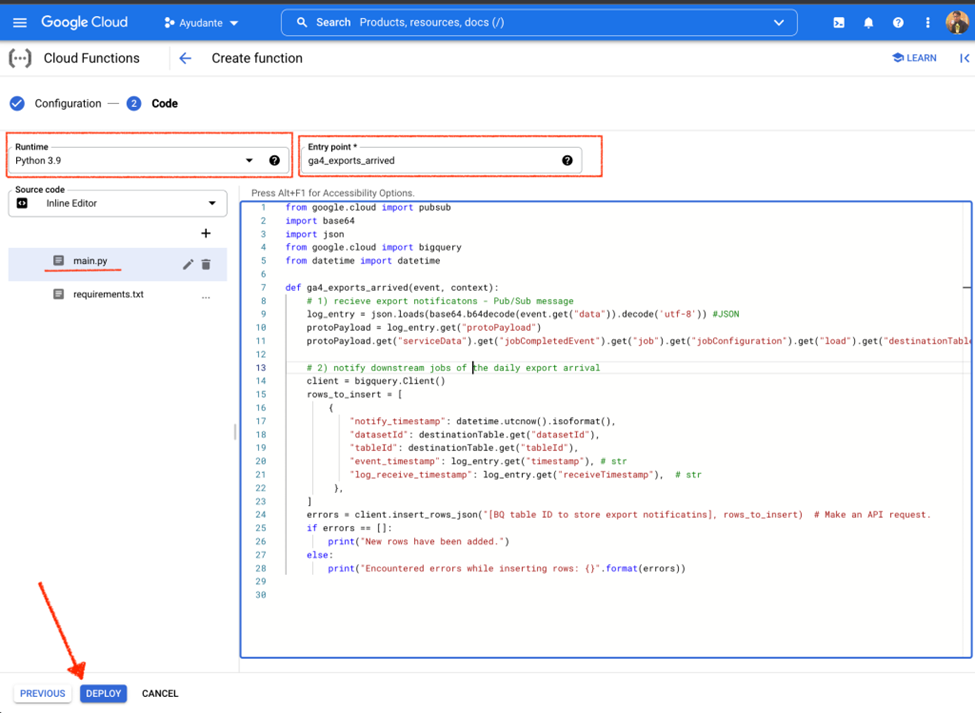
In the code section (main.py), delete all that is pre-populated and replace with the following custom code
from google.cloud import pubsub
import base64
import json
from google.cloud import bigquery
from datetime import datetime
def ga4_exports_arrived(event, context):
# 1) receive export notifications - Pub/Sub message
log_entry = json.loads(base64.b64decode(event.get("data")).decode('utf-8'))
protoPayload = log_entry.get("protoPayload")
destinationTable = protoPayload.get("serviceData").get("jobCompletedEvent") \
.get("job").get("jobConfiguration") \
.get("load").get("destinationTable")
# 2) notify downstream job
client = bigquery.Client()
rows_to_insert = [
{
"notify_timestamp": datetime.utcnow().isoformat(),
"datasetId": destinationTable.get("datasetId"),
"tableId": destinationTable.get("tableId"),
"event_timestamp": log_entry.get("timestamp"), # str
"log_receive_timestamp": log_entry.get("receiveTimestamp") # str
},
]
errors = client.insert_rows_json("[Your BQ table ID to store export notificatins], rows_to_insert) # Make an API request.
if errors == []:
print("New rows have been added.")
else:
print("Encountered errors while inserting rows: {}".format(errors))
——————————————————————————————————–
UPDATE (2022.05.25): if you are using a new BigQueryAuditMetadata version of logs, as mentioned in UPDATE above (STEP1), do adjust this Cloud Functions slightly to match BigQueryAuditMetadata schema of the logs. Instead protoPayload.get(“serviceData”).*, you will fetch destination table full path as protoPayload.get(“resourceName”). Updated Cloud Function will look like this
from google.cloud import pubsub
import base64
import json
from google.cloud import bigquery
from datetime import datetime
def ga4_exports_arrived(event, context):
# 1) receive export notifications - Pub/Sub message
log_entry = json.loads(base64.b64decode(event.get("data")).decode('utf-8'))
protoPayload = log_entry.get("protoPayload")
destinationTable = protoPayload.get("resourceName")
# 2) notify downstream job
client = bigquery.Client()
rows_to_insert = [
{
"notify_timestamp": datetime.utcnow().isoformat(),
"datasetId": destinationTable.split("/")[3],
"tableId": destinationTable.split("/")[5],
"event_timestamp": log_entry.get("timestamp"), # str
"log_receive_timestamp": log_entry.get("receiveTimestamp") # str
},
]
errors = client.insert_rows_json("[Your BQ table ID to store export notificatins], rows_to_insert) # Make an API request.
if errors == []:
print("New rows have been added.")
else:
print("Encountered errors while inserting rows: {}".format(errors))
——————————————————————————————————–
As you can see our custom code has 2 sections:
- The 1st part receives a Pub/Sub message (which in our case is the daily export event log, sinked from Cloud Logging to Pub/Sub). This message includes event log metadata like which table name was exported, at what time etc.
- The 2nd part processes this message and notifies a downstream job of the new export table ingested into BigQuery. In our case, for the sake of simplicity. we are storing it in BigQuery. In real world application it will be something which your downstream job can read and act upon, for ex. HTTP hook, another Pub/Sub topic etc. or even Email or Slack notification, or BigQuery Scheduled query. Something to work out with your downstream data team that ingest daily export into their data pipeline.
Add these 2 lines in “requirements.txt”
google-cloud-pubsub
google-cloud-bigquery
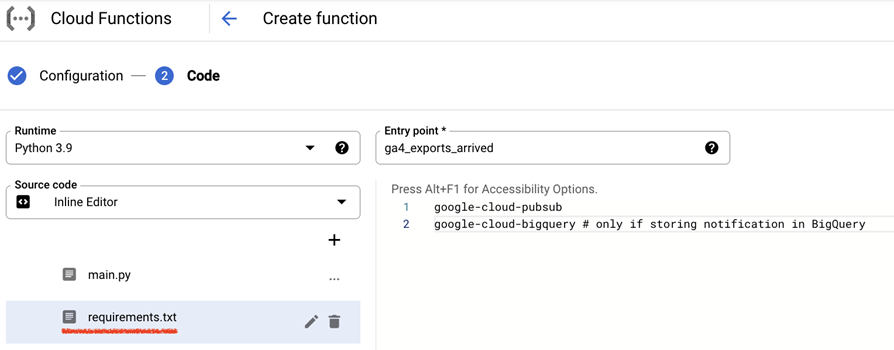
Click Deploy
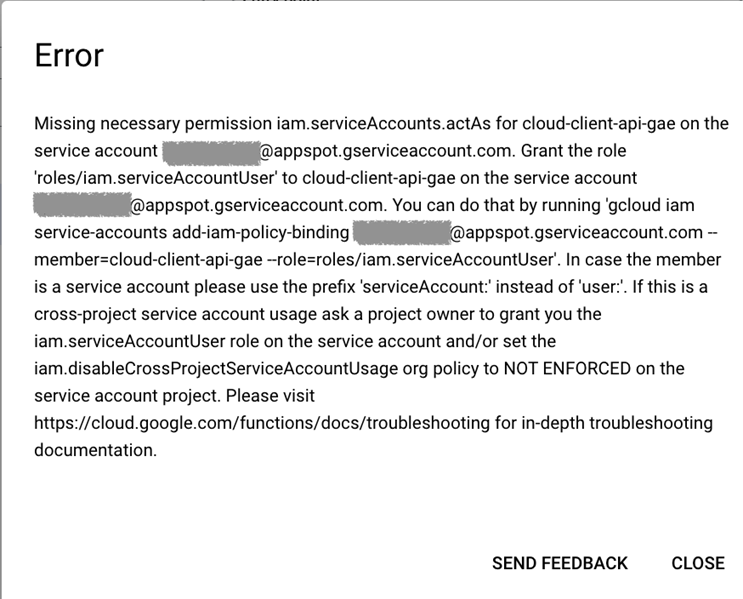
During Deploy, In some cases you may encounter this error. You can fix this by giving your Google Account user (your GCP Project user email) a Service Account User (roles/iam.serviceAccountUser) role on Cloud Function Runtime Service Account, an account that the function will assume as its identity (as we stated above by default this is App Engine default service account PROJECT_ID@appspot.gserviceaccount.com unless you specify a different runtime service account when deploying a function)
Wait 1-2 minutes and the Cloud function will deploy successfully.
By now, if you follow all the steps successfully, BigQuery export notification solution is fully deployed and up and running. Wait for the next daily export to arrive. As new export arrives in BigQuery, Pub/Sub will receive export log notifications, subsequently executing the cloud functions code.
As for our deployment, our custom code is storing these notifications in another BigQuery table, this is what we see as daily exports arrive.
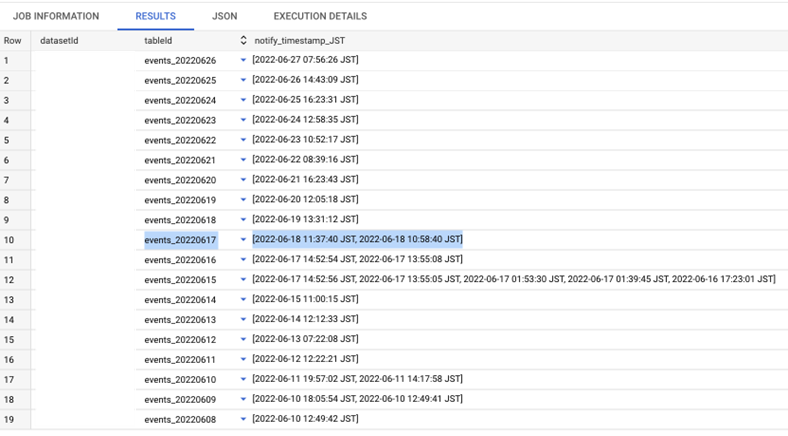
You might notice some exports report multiple notify_timestamp_JST, meaning after the table is first exported (creation time) it was re-exported by GA4 (modified time). Like we mentioned in the very beginning – GA4 export for a specific date may happen multiple times (not in a single shot) because in GA4, events are processed if they arrive up to 72 hours late (so called “late-hits”).
Let’s see a row for events_20220617 and compared with actual Table Info in BigQuery
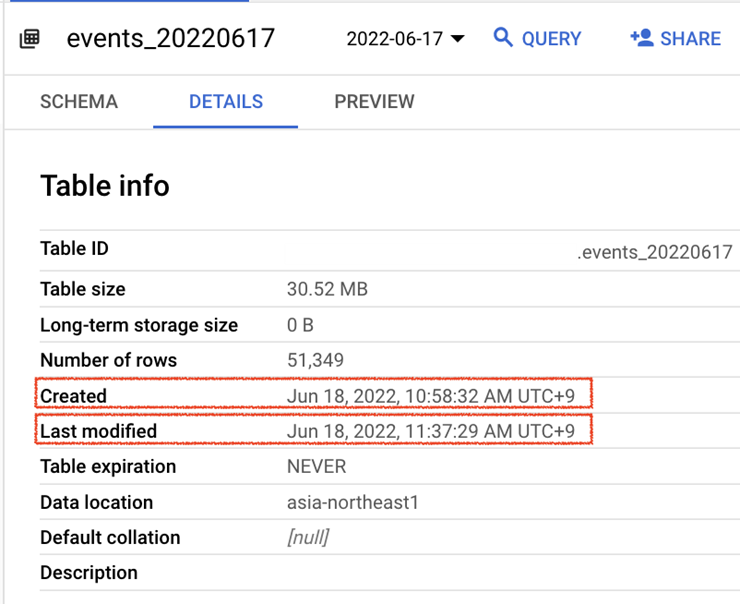
We can confirm both the Table Created time (Jun 18, 2022, 10:58:32 AM UTC+9) and the Last modified time (Jun 18, 2022, 11:37:29 AM UTC+9 ) are matching (a few seconds delay, <10sec, between actual event time and our function received the event log)
Further improvements for future
We’ve seen GA4 export for a specific date’s table may happen incrementally over multiple times. This is different behavior than how old Universal Analytics export behaves (those arrive in one single load in a relatively more predictable manner).
One question remains – specifically for a downstream job designed to extract and load daily export to an external database. How to ensure, each time a new export for a specific date arrives in BigQuery, the downstream job only reads the incremental load (OR only notify downstream job of the last export for a specific date’s table). Otherwise that would lead to duplicate data in the external database. We have not been able to incorporate any logic into our solution yet to avoid such behavior, there’s no way to know that (at least we are not aware). One potential solution shared by Analytics Canvas’s ”James Standen” (see entire discussion on #measure slack channel) is having downstream do an incremental load that always loads the last n days data and then on scheduled refresh deletes the last n days, and reloads them. Let us know if there is any other better way to manage such situation.
As we have shown, it is possible to build a robust, reliable GA4 BigQuery export notification solution using GCP services, so that your downstream jobs always work in predictable fashion, have fresh data available, and savings your team’s time and attention each time exports are delayed and keep them focussed on main job.