※この記事はMarketing Landの許諾を得て、以下の記事を翻訳したものです。
“How Machine Learning Works, As Explained By Google”

Googleが一部の検索を処理に機械学習を利用していると発表され、機械学習と人工知能が注目のテーマになっている。機械学習とは? 機械がどうやって自ら学習しているのか? こちらの記事ではGoogle社で機械学習に関わる人からの背景情報を紹介する。
昨日(米国日時11月3日)Googleはテクノロジージャーナリスト向けに「機械学習の基礎」というイベントを開催し、私も参加した。基礎と言われたイベントでも、かなり技術的な話が多く、私や、他の何人かの参加者には簡単には理解できない内容だった。
例えば、発表者が機械学習の数学的な部分が「簡単だ」と言いながら、同じ文書で微積分の話を含んでいる。発表者と一般人の「簡単」の定義が違っているのだ!
しかしながら、機械(コンピューター)が物、テキスト、話し言葉を認識できるようになる自修のプロセスと要素を以前よりは、理解できたと思う。
下記が、私が重要と思ったポイントである。
機械学習の構成要素
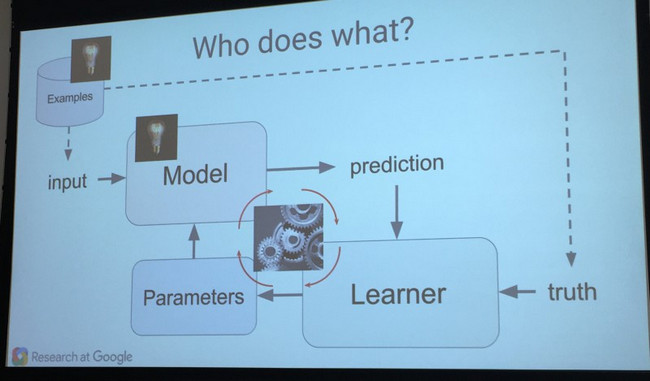
機械学習のシステムは3つの主な要素に基づいている。
- Model(モデル):認識、または推定するシステム
- Parameter(パラメータ):モデルの決断が基づくシグナル・要素
- Learner(学習器):推定と実際の結果を比較し、パラメータを調整、さらにそれによってモデルを調整するシステム
Google社のシニア研究者と深層学習チームの創設者のGreg Corrado氏が話した内容に基づいて、上記のコンセプトを、例を使って説明してみる。
あなたは教師だとしよう。学生がテストの最高点数を取るのに必要な勉強時間を決めたいとする。回答を出すのに機械学習を利用する。もちろんこんな例には機械学習を使うのはオーバーだが、とてもシンプルな説明になる。
モデルの設計
機械学習システムが使うためのモデルがすべての始まり。少なくともこういう例の場合、モデルを機械に提供するのは人間だ。上記の例では、学生はテストで最高点数を取るのに5時間の勉強が必要だというモデルを、教師が機械に入力する。
モデル自体はその計算に利用されるパラメータに影響される。
この場合、パラメータは勉強の時間とテストの評価点になる。
パラメータは下記になるとする。
- 0時間 = 点数50%
- 1時間 = 点数60%
- 2時間 = 点数70%
- 3時間 = 点数80%
- 4時間 = 点数90%
- 5時間 = 点数100%
上記を表すのに機械学習のシステムが数式を利用し、推定のトレンドラインを作成する。例は下記の図になる。
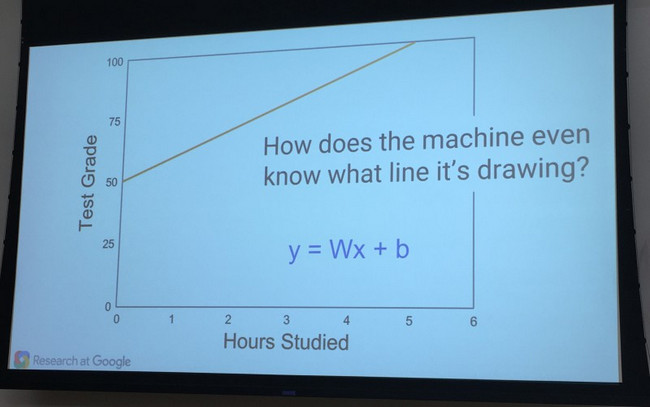
初期入力
モデルが設定されたら、実際の情報を入力する。例では、教師が4人の生徒の点数と勉強時間を入力する。こちらの例の場合、点数がモデルと一致しない。トレンドラインより高い、また低い点数である。

機械学習の部分がここから始まる。
学習器が学習する
上記入力した点数は何になるのか? このように学習器に入力されたデータは、機械学習でモデルを磨くための自修に利用されるため、「トレーニングセット」あるいは「トレーニングデータ」と呼ばれる。
学習器が点数を元のモデルと比較し、差を確認する。また、計算をして、初期の推定値を調整する。例えば、上記記載していたリストが下記のように修正されるかもしれない。
- 0時間 = 点数45%
- 1時間 = 点数55%
- 2時間 = 点数65%
- 3時間 = 点数75%
- 4時間 = 点数85%
- 5時間 = 点数95%
- 6時間 = 点数100%
新しい推定では、最高点数を取るのに勉強時間がもっとかかることを表すようにモデルが調整される。
こちらはプロセスを見せるために作られた例だが、重要なのは、学習器がパラメータに細かい調整を行い、モデルを磨いているということだ。
リンス&リピート
システムがもう一度新しい点数で実行される。こちらの点数が調整されたモデルと比較される。それが成功しているなら、新しい数値がモデルの推定数値と近づいているはずだ。

しかし、これらはまだ完璧とはいえない。そのため、学習器が改めてパラメータを調整し、モデルを磨く。もう一度テストデータが使用して、比較を行って、さらにモデルを調整する。
モデルが勉強時間で点数を正確に推定できると判断されるまで、このサイクルを繰り返す。
最急降下法: 機械学習が崩壊を防ぐために

Google社のCorrado氏によると、ほとんどの機械学習のコンセプトは「最急降下法」(Gradient Descent)、またはGradient Learning(勾配降下学習)として知られている。その意味は、システムが正確になるまで小さい調整を繰り返し続けることを意味している。
Corrado氏がこれを険しい山から下りることと比較した。跳んだり、走ったりすると危ないし、間違って落ちてしまう可能性が高い。それよりも少しずつ、気をつけながら降りることが必要なのだ。
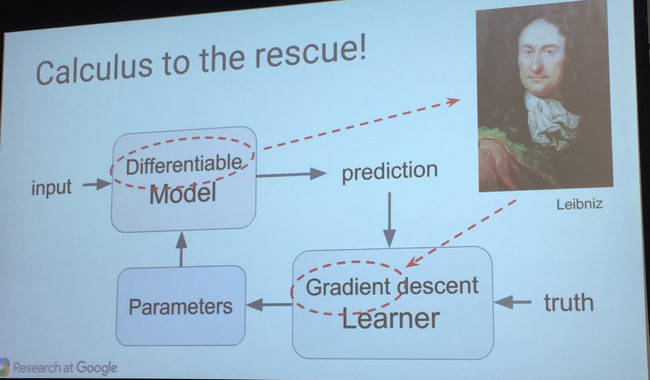
記事の初めに機械学習が「数学的には簡単」と書いたが、数学得意な人なら、機械学習に関わる数式は確かにとても簡単に思われるでしょう。
逆に難しいのは、処理のキャパと関連するもの。上記のようなステップを踏み、自修するのは非常に時間がかかるプロセス。しかし、現在のコンピューターは早く、大きくなってきているため、何年か前では考えられない機械学習が当たり前のことになりつつあるのだ。
ちょっとカッコつける:猫を認識する
前の例は非常に簡単だ。すでに述べた通り、教師がテストの点数を推定するのに機械学習を使うのはオーバーだ。しかし、同様に簡単なシステムが非常に複雑なこと、例えば、猫の写真を認識するのにも利用されている。
コンピューターは人間のような視力がない。Googleが下記のような写真を認識する場合、コンピューターはどうやって物を認識しているのか。

それこそまさに、機械学習だ! 上記の例と同じようなプロセスで進められる。猫であることを画像、色、形等で認識できるようにモデルを設計。その次に猫の画像を提供して、モデルの正確性を確認する。学習器が調整し、学習サイクルが続く。しかし猫のような物の認識は非常に難しい。画像をパターンに変換し、システムが物とマッチできるように大量なパラメータ、パラメータの中のパラメータを使用するのだ。
下記は、システムがカーペットの上にいる猫を認識するかもしれない画像。

この絵のような画像は、Googleが発表したDeepDreamコードに基づいて「Deep Dream」と呼ばれる。DeepDreamコードは、Googleの機械学習システムが、物を認識するためにパターン作成することについての情報共有としてリリースされた。
この画像は、学習のプロセスの例というより、コンピューターが猫を認識する際に探すパターンの種類を例である。もし機械に視力があったら、上記の画像のような物が見えているだろう。
ちなみに、画像認識の場合、1回目の例と違って初期のモデルが人間ではなく、機械に設計されることが違いになる。機械が自身で初期の色、形等の要素をグループ化して、物を認識するようにし、トレーニングデータを利用してモデルを磨いていく。
シチュエーションの認識
こちらのような学習がどれぐらい複雑になるかを表すため、物だけでなく、シチュエーションを認識したい場合を考える。Googleの説明によると、人間がガイダンスを行って、物と物の組み合わせがシチュエーションを意味することを機械に理解させるためには、常識のルールを人が入力することで手伝いをする必要がある。

- コンピューターの認識:
- 小さい人物、バスケット
- 小さい人物、バスケット
- 卵
- 人間の認識:
- イースターエッグ集め!
上記の例では、コンピューターは小さい人物、バスケットと卵を認識している。しかし、人間は、これらすべてのものを見て、シチュエーションのイースターエッグ集めとして認識する。
RankBrainへの影響は?
このような機械学習がRankBrainとどのように関係するのか? Google社はその詳細については一切説明していない。正式なQ&Aの中にも話題に上がらず、休憩中の談話の中でも、既に発表されている情報以外のものはなかった。
その理由は、競合性にあるだろう。Google社は総合的な機械学習の情報についてはよく共有しているが、検索に関してのユニークで重要と見なされる具体的な情報については共有していない。
もっと知りたいなら
機械学習についてもっと学びたいならGoogleの研究ブログ、また、研究論文を参照してほしい。また、概要を説明する動画も公開されている。