GA4プロパティとBigQueryをリンクすることにより毎日エクスポートされるデータを日次レポートやマーケティングオートメーションの動作条件に使用する場合、皆さんは、前日のトラフィックデータ(前日のevents_YYYYMMDDという名前のテーブル)のエクスポートが完了する正確なタイミングと、このデータを利用するダウンストリームジョブを起動できるタイミングをどのように把握するかという問題に直面するでしょう。日次エクスポートは決まった時間に実行されず、これを通知する仕組みも用意されていません。
解決したい問題
GA4の日次エクスポートが遅延する度にダウンストリームジョブの実行に失敗して、Googleサポートやヘルプデスクへの問い合わせ、工数のロスト、ストレスからの気分転換など、BigQueryのデータが到着するまで予測不能な長い待ち時間が発生してしまうという問題。
よくある解決策と課題
- ダウンストリームジョブの実行開始タイミングを日次エクスポートが完了していると思われる時間まで何時間か遅らせる。
- ただしエクスポートされたデータが予想よりも早く到着した場合でもデータにアクセスできるタイミングが遅くなります。また、エクスポートが予期せず1日か2日遅れた場合はどのように対処すればいいのでしょうか。
- エクスポートが完了したかどうか定期的にチェックし続ける。(例:ダウンストリームジョブをトリガーする前に< events_YYYYMMDD >テーブルの存在を確認する。)
- この方法もまたデータにアクセスできるタイミングを遅らせる上、データパイプラインをさらに複雑なものにします。
これらの解決策はいずれも失敗率を減らし、安定性を向上させることができますが、それでも不安定なエクスポートのタイミングに完全に対応できるものではありません。また、私たちはGA4のエクスポートタイミングが非常に予測困難であることを確認しています。
- エクスポートされたデータは翌日の早朝7-8時に到着する場合もあれば、昼過ぎ、午後6-7時以降、あるいは翌日に到着する場合もあります。
- さらに、GA4では、イベントが最大72時間遅れて到着した場合(いわゆる「レイトヒット」)でもイベントが処理されるため、特定の日付のエクスポートが(シングルショットではなく)複数回発生する場合があります。
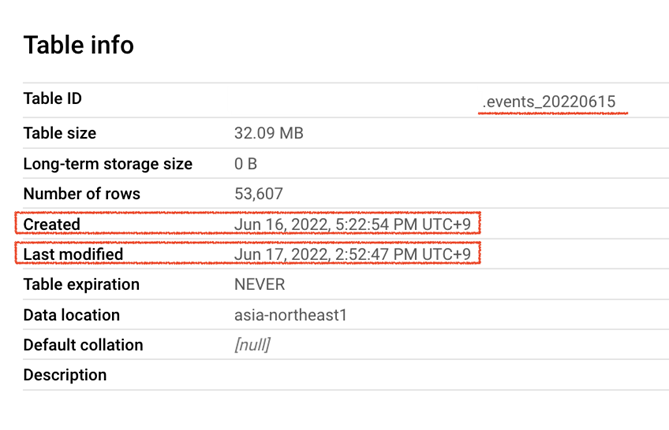
以下のスクリーンショットでは、 events_20220615のエクスポートは、最初に6月16日(作成時刻)に発生し、次に6月17日(変更時刻)に再び発生しています。
解決策 – Cloud Event Driven Solution
本記事では、これらの問題を解決するために、GA4 BigQueryのエクスポート通知のためのCloud Event Drivenソリューションを提案します。また、これらをすべてGoogle Cloud Platform(GCP)に完全に実装するためのステップバイステップガイドも提供します。この記事では以下のGCPコンポーネントを使用します。
Cloud Logging
GCPプロジェクトで発生したすべてのイベントに関する情報を、構造化されたログ形式で保存する仕組み。BigQueryデータセット/テーブルを作成したとき、BigQueryテーブルに対してクエリを発行したとき、あるいはプロジェクトにユーザー権限を追加/削除したときなど、これらのクラウドイベントはすべてCloud Loggingにログとして記録されます。GCPプロジェクトで何が起こっているのか知りたいときは、この機能を利用するとよいでしょう。新しいGA4エクスポートテーブルが到着すると、このイベントはすぐにCloud Loggingに記録されます。このログエントリを使用して、通知をトリガーします。
Pub/Sub
パブリッシャートピック(イベントデータが送信されるところ)とリンクされたサブスクライバー(これらのイベントデータを個別にリッスンする)の両端により構成されるスケーラブルなイベント取り込みメッセージングキューシステム。サブスクライバーはイベントデータが発行されたときに、いくつかのカスタムコードを通して任意のビジネスロジックを使ってイベントデータを処理することができます。
Cloud Functions
サーバーレスのクラウド実行環境でカスタムコードを実行する仕組み(現在、Python / Go / Java / Node.js / PHP / Rubyがサポートされています)。単一目的のコードを記述し、コードが実行されるタイミングのトリガーを設定することで使用できます。現在サポートされているトリガーは、関数のエンドポイントへのHTTPリクエスト、Pub / Subトピックにパブリッシュされたメッセージ、Cloud Storageから作成/変更/削除されたファイルオブジェクトなどです。
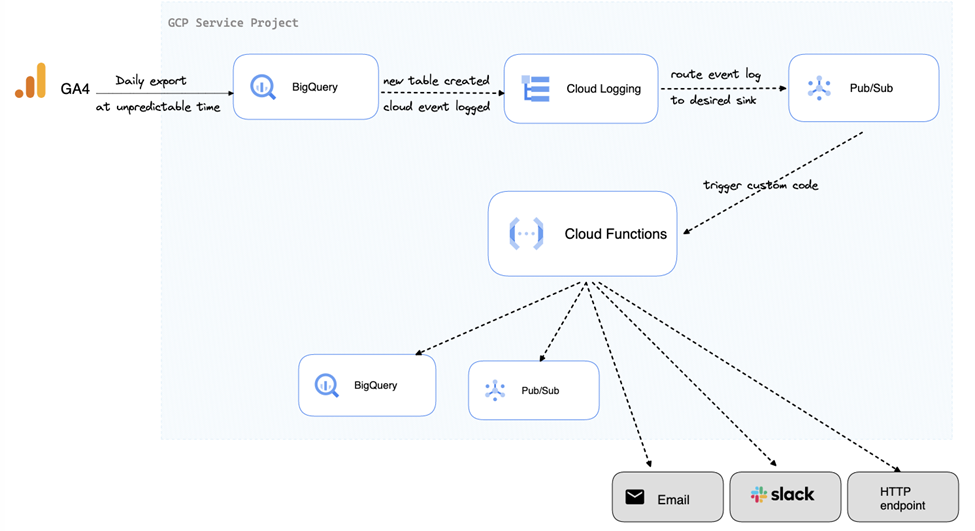
使用するアーキテクチャ
これらのGCPコンポーネントを使用したBigQueryエクスポート通知ソリューションのアーキテクチャは以下のようになります。
実装ガイド
●STEP1
ログエクスプローラに移動し、以下のクエリをコピーしてクエリボックスに貼り付けます。(クエリボックスが表示されない場合は、右側の[クエリを表示]トグルをオンにします)
resource.type = "bigquery_resource"
protoPayload.authenticationInfo.principalEmail = "firebase-measurement@system.gserviceaccount.com"
protoPayload.serviceData.jobCompletedEvent.eventName = "load_job_completed"
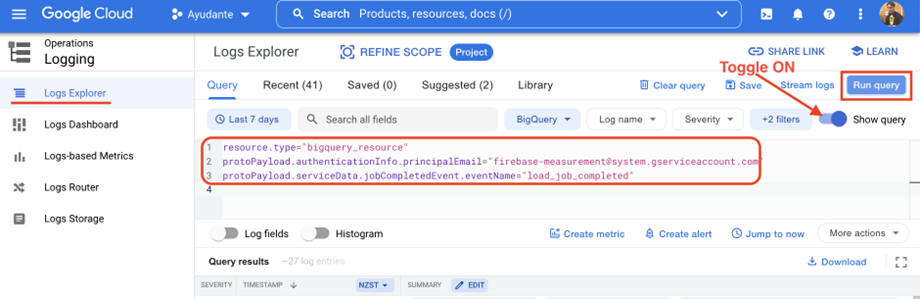
右側の「クエリを実行」ボタンを押します。
——————————————————————————————————-
UPDATE (2022.05.25): 上記の内容で取得している監査ログデータは古いバージョンのBigQueryログなので、新たに実装する場合は新しいバージョンであるBigQueryAuditMetadata形式のログを使用することをお勧めします。これに合わせてCloud Functionsのコードも若干調整します(下記STEP3参照)。
resource.type="bigquery_dataset"
protoPayload.authenticationInfo.principalEmail="firebase-measurement@system.gserviceaccount.com"
protoPayload.serviceName: "bigquery.googleapis.com"
protoPayload.methodName="google.cloud.bigquery.v2.JobService.InsertJob"
protoPayload.metadata.tableDataChange.reason="JOB"
——————————————————————————————————-
この操作により、以前のエクスポートからのすべてのイベントログが表示されます。(結果が表示されない場合は、既にエクスポートが完了している過去数日間を含めるように日付範囲を広げてみてください)
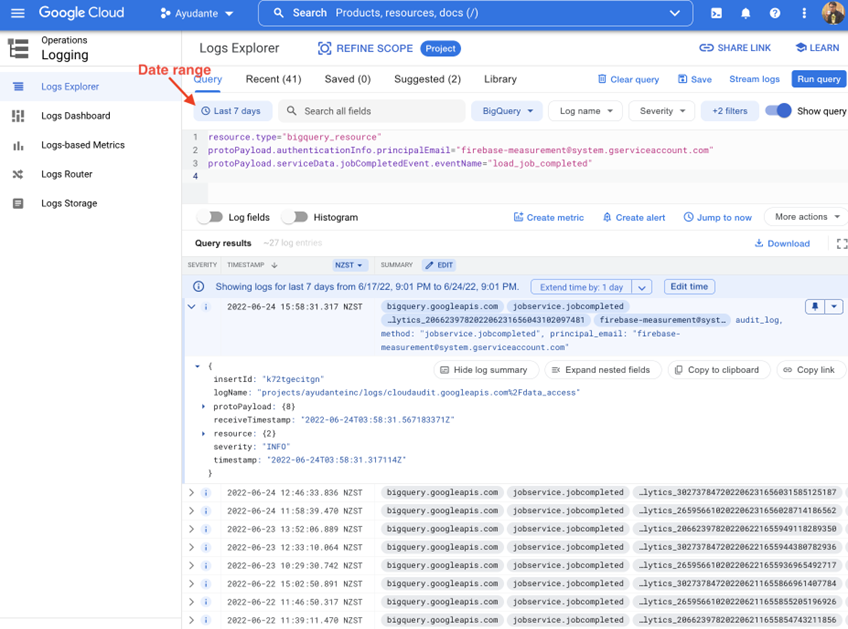
ここでは、クラウドイベントログを以下の条件をすべて満たすログのみにフィルタリングしています。
- bigquery_resourceに関連するログである。
- ユーザー firebase-measurement@system.gserviceaccount.com (GA4のエクスポートを担当するサービスアカウントのメールアドレス)により実行されたログである。
- load_job_completedイベントに関連するログである。(GA4からの日次エクスポートはloadジョブとしてBigQueryに取り込まれます。このジョブの完了はエクスポートがBigQueryに取り込み完了したことを示します。)
各ログエントリの結果を展開することで、それぞれの日次エクスポートイベントに関連する監査データを調べることができます。(例:GCPプロジェクトID、BigQueryデータセットID、テーブルID、正確なエクスポート時間など)キーの完全なリストは公式ドキュメント( LogEntry 、 AuditLog 、 BigQuery AuditData )をご確認ください。これらのフィールドを利用することで更にログをフィルタリングして、欲しい特定のデータセットID(日次エクスポート通知の目的ではGA4プロパティIDに相当)のログだけに絞りこみます。
UPDATE (2022.05.25): 上記の内容で取得しているAuditDataは旧バージョンのBigQueryログなので、新たに実装する場合は、新しいバージョンのBigQueryAuditMetadataを使用することをお勧めします。これに合わせてCloud Functionsのコードも若干調整します(下記STEP3参照)。
●STEP2
このステップでは、GA4の日次エクスポートがBigQueryに到着したときに、Pub/Subトピックに通知する仕組みを設定します。
ログエクスプローラーの結果画面(STEP1)で、[その他の操作]ドロップダウン(または単に「操作」と表示される場合があります)—>[シンクの作成]をクリックします。
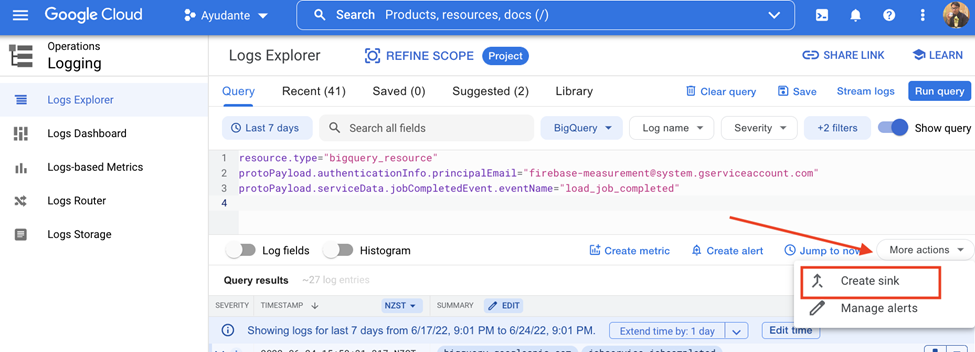
新しいウィンドウ(「ログルーター」画面)が開きます。
「シンク名」フィールドと「シンクの説明」フィールドに何か入力してください。(こちらの例ではシンク名に GA4_export_arrived を入力し、説明を空白のままにしています)。
「次へ」をクリックします
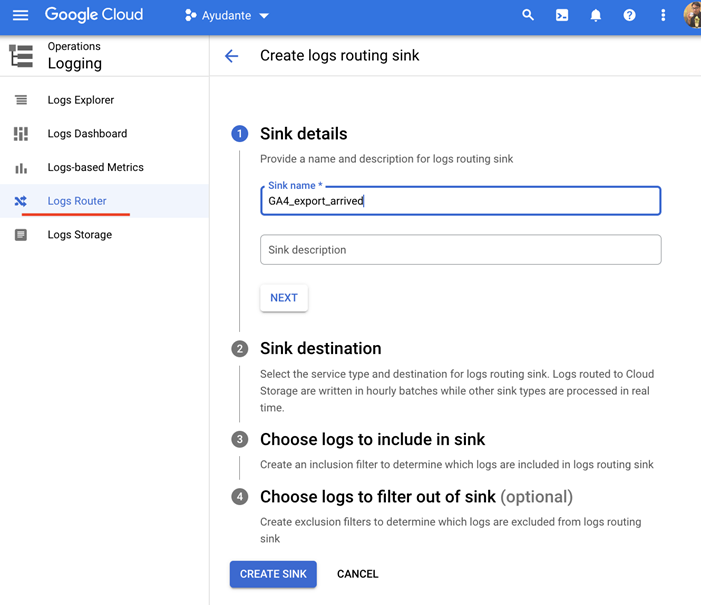
「シンクの宛先」の下
[シンクサービスの選択]ドロップダウンをクリックします—>[Cloud Pub/Sub トピック]を選択します
[Cloud Pub/Sub トピックを選択してください]ドロップダウンをクリック→[トピックを作成する]をクリックします
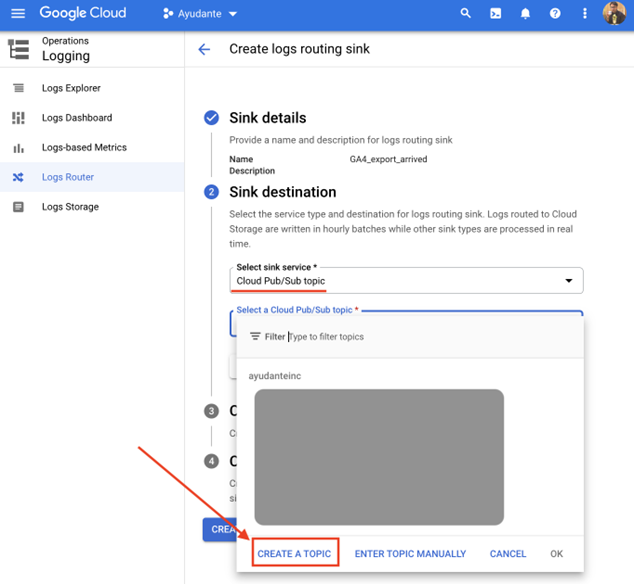
新しい「トピックの作成」オーバーレイ画面が表示されます。任意の「トピックID 」名を入力し(こちらの例では ga4_exports_arrived を入力しました)、残りのオプションはデフォルトのままにして、「トピックを作成」をクリックしてから「シンクの作成」をクリックします。
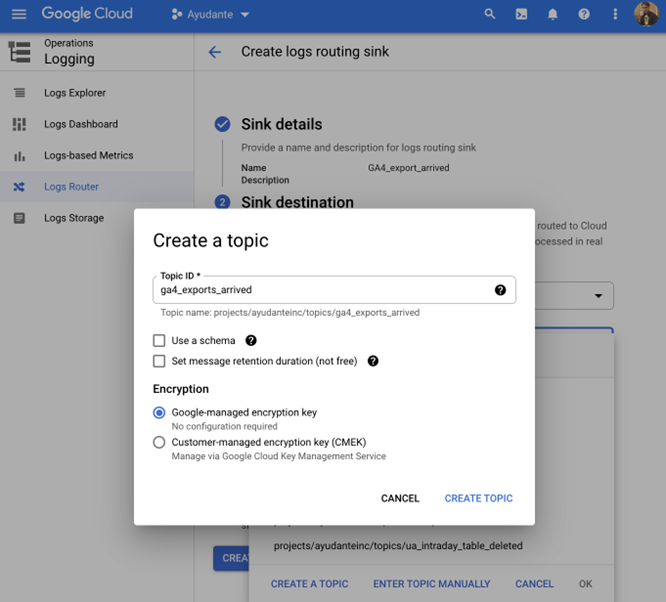
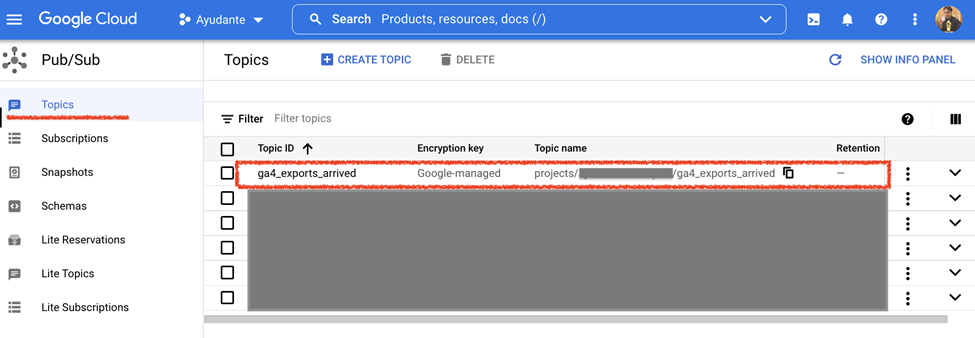
これらがすべて設定された後 GCPプロジェクト内のPub / Subサービスに移動すると、作成したばかりの新しいパブリッシャートピックに気付くでしょう。ここまでの手順で行ったことは、新しい日次エクスポートデータが到着するたびに、このパブリッシャートピックに通知が送信されるようにすることです。
——————————————————————————————————-
UPDATE (2022.05.25): もし複数プロジェクト間を跨がる設定を行う場合、シンクを使用して異なるプロジェクト間でログを転送するための追加の権限付与設定が必要です。
https://cloud.google.com/logging/docs/export/configure_export_v2#dest-auth
——————————————————————————————————-
●STEP3
ここからは、上記で作成したパブリッシャートピックに送信された新しいメッセージをリッスンし、新しいメッセージが送信されるたびにカスタムコードを実行するCloud Funtionsをデプロイします。
Cloud Functionsに移動し、「関数の作成」をクリックします
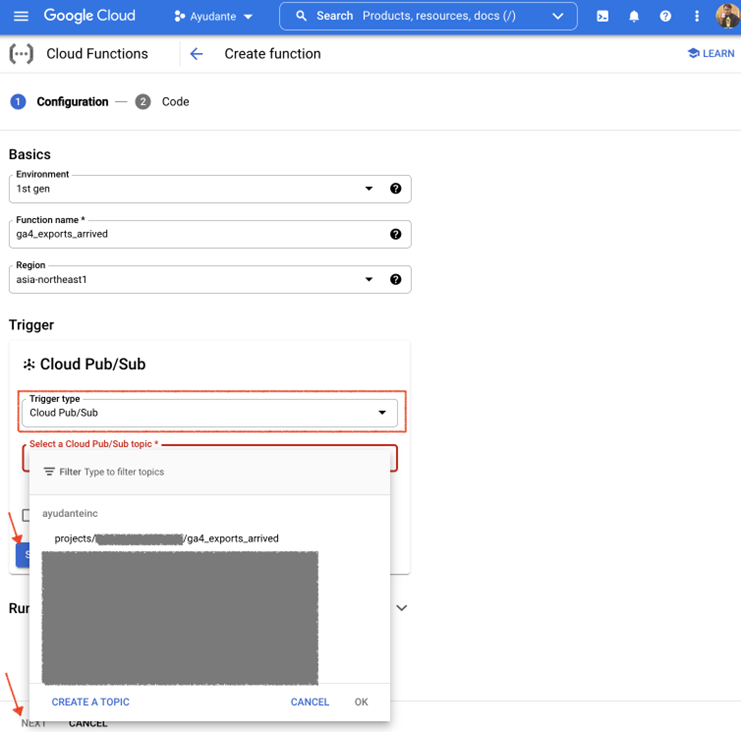
次に表示される「1.設定」のステップにて:
任意の「関数名」を入力します(こちらの例では ga4_export_arrived を入力しました)。
パブリッシャートピックと同じ「リージョン」を選択します(クラウドプロジェクトの組織ポリシーにリソースの場所の制限の組織ポリシーがない限り、通常はどのリージョンでも機能します)。 こちらの例では asia-northeast1 (東京)を選択しました。
トリガーの項目で “トリガーのタイプ “のドロップダウンをクリックして、”Cloud Pub/Sub “を選択します。
[Cloud Pub/Sub トピックを選択してください]のドロップダウンで、前の手順で作成したパブリッシャートピックを選択します。
「保存」ボタンをクリックしてから「次へ」をクリックします
Cloud Functionsに詳しい方であれば、この画面でその他の詳細な設定(例:メモリ量、タイムアウト時間、自動スケーリング、サービスアカウントなど)を行うことも可能ですが、デフォルトの設定でも問題なく機能します。
セキュリティに関する注意事項 – デフォルトでは、Cloud Functionsは自動的に作成されたApp Engine default service accountのメール PROJECT_ID@appspot.gserviceaccount.com をランタイムIDとして使用します。こちらは本番環境での使用はお勧めしませんが、今回の試作目的では、デフォルトの設定にこれ以上変更を加えずにそのまま設定を進めます。
次の画面「 2.コード」では、以下のように表示されます。
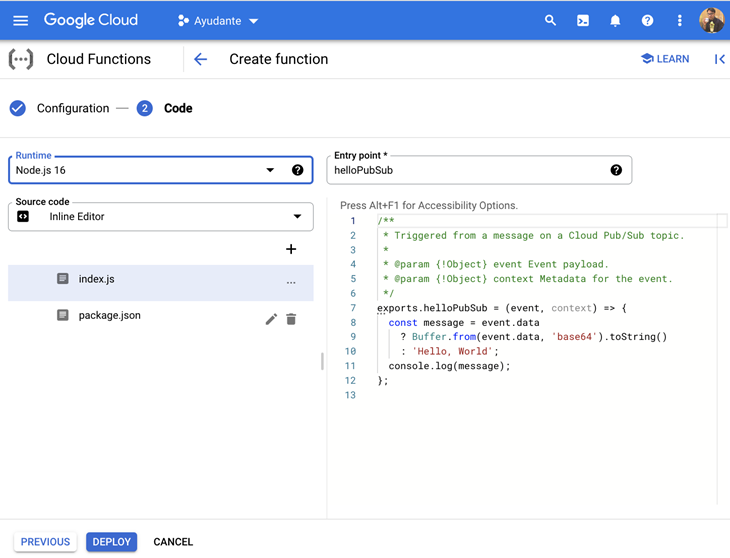
[ランタイム]ドロップダウンで、Python 3.9(または利用可能な最新のもの)を選択します。この例ではPythonランタイムを選択しましたが、カスタムコードを作成するために好きな他のランタイム(Go / JAVA / Node.js / PHP / Ruby)を選択することも可能です。
「エントリポイント」フィールドに関数名を入力します。任意の名前を使用できますが、カスタムコード内で使用する関数名と一致している必要があります。以下のコードを使用する場合、関数名は ga4_export_arrived を使う必要があります。
コードセクション(main.py)で、事前に入力されているものをすべて削除し、次のカスタムコードに置き換えます。
from google.cloud import pubsub
import base64
import json
from google.cloud import bigquery
from datetime import datetime
def ga4_exports_arrived(event, context):
# 1) receive export notifications - Pub/Sub message
log_entry = json.loads(base64.b64decode(event.get("data")).decode('utf-8'))
protoPayload = log_entry.get("protoPayload")
destinationTable = protoPayload.get("serviceData").get("jobCompletedEvent") \
.get("job").get("jobConfiguration") \
.get("load").get("destinationTable")
# 2) notify downstream job
client = bigquery.Client()
rows_to_insert = [
{
"notify_timestamp": datetime.utcnow().isoformat(),
"datasetId": destinationTable.get("datasetId"),
"tableId": destinationTable.get("tableId"),
"event_timestamp": log_entry.get("timestamp"), # str
"log_receive_timestamp": log_entry.get("receiveTimestamp") # str
},
]
errors = client.insert_rows_json("[Your BQ table ID to store export notificatins], rows_to_insert) # Make an API request.
if errors == []:
print("New rows have been added.")
else:
print("Encountered errors while inserting rows: {}".format(errors))
——————————————————————————————————-
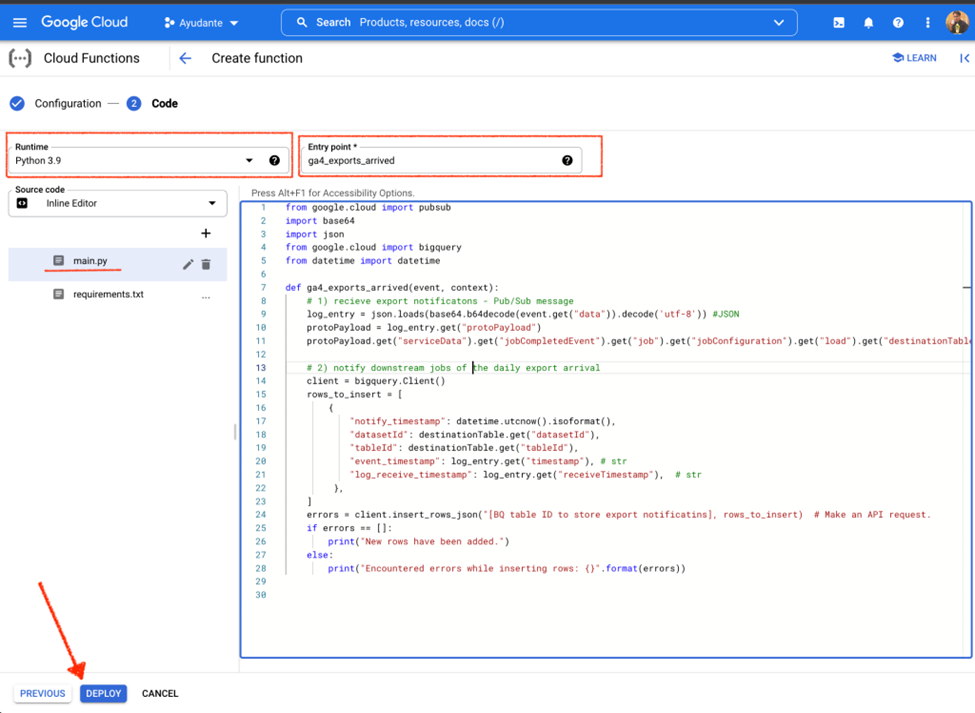
UPDATE (2022.05.25): 上記(STEP1)のUPDATEで述べたように新しいバージョンのBigQueryAuditMetadata形式のログを使用する場合、ログのBigQueryAuditMetadataスキーマに合わせて
protoPayload.get(“serviceData”).get(“job”).get(“jobConfiguration”).get(“load”).get(“destinationTable”) を利用する代わりに protoPayload.get(“resourceName”) を使用して保存先テーブルのフルパスを取得して利用するために以下のCloud Functionsのコードを使用してください。
from google.cloud import pubsub
import base64
import json
from google.cloud import bigquery
from datetime import datetime
def ga4_exports_arrived(event, context):
# 1) receive export notifications - Pub/Sub message
log_entry = json.loads(base64.b64decode(event.get("data")).decode('utf-8'))
protoPayload = log_entry.get("protoPayload")
destinationTable = protoPayload.get("resourceName")
# 2) notify downstream job
client = bigquery.Client()
rows_to_insert = [
{
"notify_timestamp": datetime.utcnow().isoformat(),
"datasetId": destinationTable.split("/")[3],
"tableId": destinationTable.split("/")[5],
"event_timestamp": log_entry.get("timestamp"), # str
"log_receive_timestamp": log_entry.get("receiveTimestamp") # str
},
]
errors = client.insert_rows_json("[Your BQ table ID to store export notificatins], rows_to_insert) # Make an API request.
if errors == []:
print("New rows have been added.")
else:
print("Encountered errors while inserting rows: {}".format(errors))
——————————————————————————————————-
ご覧のように、このカスタムコードは2つのセクションから構成されています。
最初の部分では、Pub / Subメッセージを受信しています(この例では、CloudLoggingからPub/ Subに送られた日次エクスポートのイベントログです)。このメッセージには、どのテーブル名がいつエクスポートされたかなどのイベントログメタデータが含まれます。
2番目の部分ではこのメッセージを処理し、BigQueryに取り込まれた新しいエクスポートテーブルをダウンストリームジョブに通知しています。この例では説明を簡単にするためにBigQueryにログを保存する処理にしていますが、実際のアプリケーションではダウンストリームジョブが HTTP hook、別のPub / Subトピック、他にはメールやSlackへの通知、BigQueryのスケジュールドクエリなど、ダウンストリームジョブがデータを読み取って動くような処理となるでしょう。このような場合、日次エクスポートデータをパイプラインに取り込んでいるデータチームと協力する必要があります。
“requirements.txt “に以下の2行を追加します。
google-cloud-pubsub
google-cloud-bigquery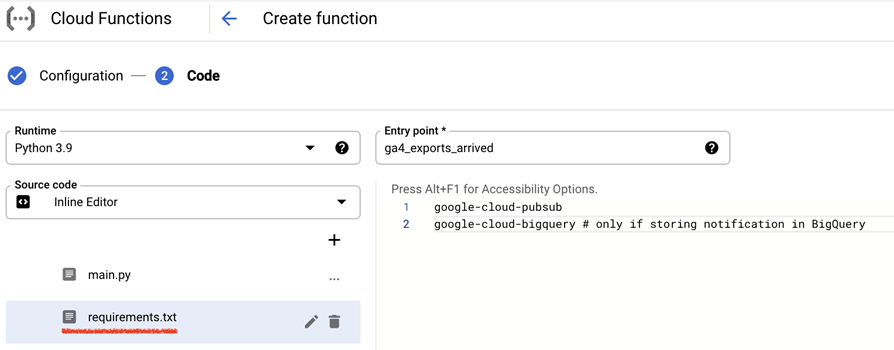
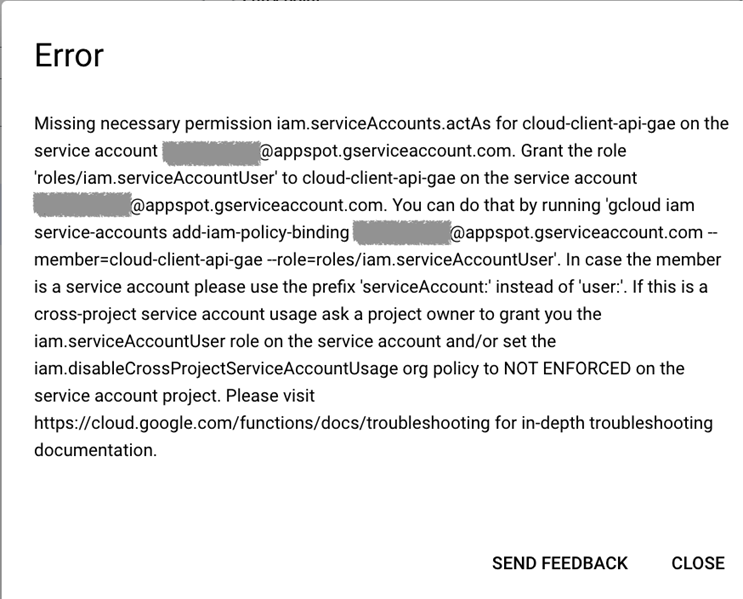
[デプロイ]をクリックします
デプロイ中に、以下のエラーが発生する場合があります。これを修正するには、あなたのGoogleアカウント(GCPプロジェクトユーザーのメールアドレス)にCloud Functionランタイムサービスアカウントのサービスアカウントユーザー( roles / iam.serviceAccountUser )ロールを付与します。このアカウントは、(前述のとおり)Cloud FunctionsがランタイムIDと見なすアカウントです。(上記のとおり、関数のデプロイ時に別のランタイム サービス アカウントを指定しない限り、App Engine default service account PROJECT_ID@appspot.gserviceaccount.com が使用されます。)
1〜2分待つと、Cloud Function が正常にデプロイされます。
この時点で、すべての手順が正常に完了していれば、GA4 BigQueryのエクスポート通知のためのCloud Event Drivenソリューションが完全にデプロイされて実行されます。次の毎日のエクスポートが到着するまで待って、新しいエクスポートがBigQueryに到着すると、Pub / Subはエクスポートログ通知を受信し、続いてCloud Functionsのコードを実行します。
この実装では、日次エクスポートが到着する際の通知情報をカスタムコードが別のBigQueryテーブルに保存しています。
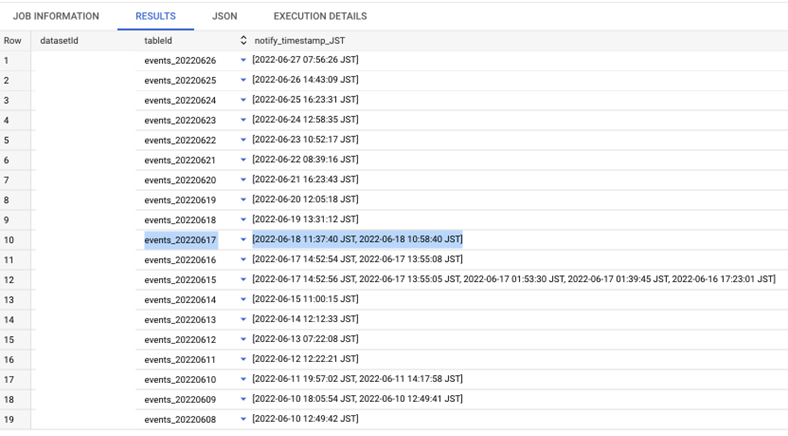
いくつかのエクスポートが複数の notify_timestamp_JST を報告していることに気づくかもしれませんが、これはテーブルが最初にエクスポートされた後(作成時間)、GA4 によって再エクスポートされた(修正時間)ことを意味します。冒頭で述べたように、GA4 では、イベントは最大 72 時間遅れて到着した場合(いわゆる “レイトヒット”)でも処理されるため、特定の日付の GA4 エクスポートは複数回発生します(一度ではありません)。
events_20220617の行を見て、BigQueryの実際のテーブル情報と比較してみましょう
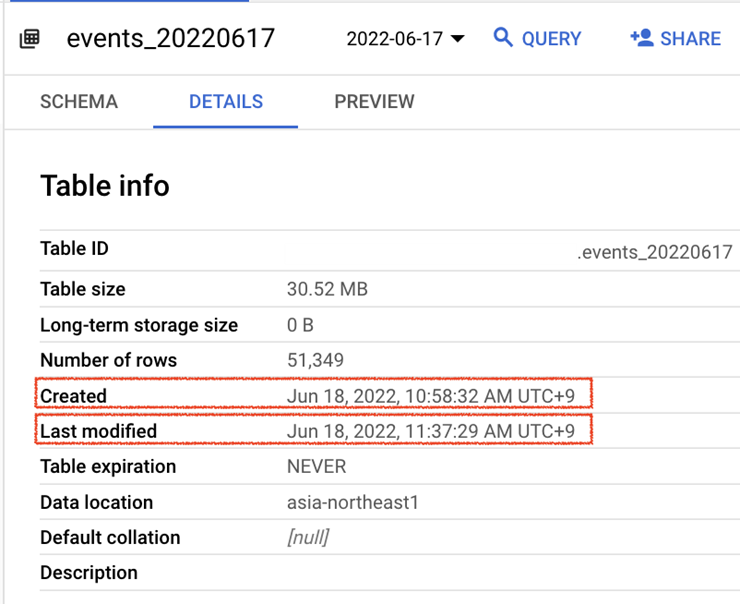
テーブルの作成時刻(Jun 18, 2022, 10:58:32 AM UTC+9)と最終変更時刻(Jun 18, 2022, 11:37:29 AM UTC+9 )の両方が一致していることを確認できます(実際のイベント発生時刻から我々の関数がイベントログを受信するまでに10秒未満の僅かな遅延が発生します。)
今後のさらなる改善に向けて
GA4 エクスポートでは、特定の日付のテーブルへのエクスポートが複数回にわたって行われる場合があります。これは、以前のユニバーサルアナリティクスのエクスポートとは異なる動作です。(ユニバーサルアナリティクスのエクスポートの場合、より安定した形で1回の読み込みでデータエクスポートが完了します)
残っている1つの課題 – 日次エクスポートデータを抽出して外部データベースに読み込むことを目的としたダウンストリームジョブの場合、特定の日付の新しいエクスポートがBigQueryに到着するたびに、ダウンストリームジョブが増分ロード分のみを読み込む(あるいは単に特定の日付のテーブルに対する最後のエクスポートをダウンストリームジョブに通知する)ようにするためには具体的にどのように対応すればよいでしょうか。この課題を考慮しないと外部データベースに重複データを発生させてしまうおそれがあります。このような挙動を回避するためのロジックはまだ我々のソリューションには組み込まれておらず、それを知る術はありません(少なくとも私たちは把握していません)。 Analytics CanvasのJamesStanden氏が共有してくれた一つの解決策は、常に過去数日間分のデータをダウンストリームに読み込ませて、スケジュールに従って過去数日分のデータを削除して最新のデータを再読み込みさせる方法です。(#measure slack channel の議論を参照) 。もしこのような状況にうまく対処できる良い方法が他にあれば是非私たちに教えてください。
本記事でご紹介したように、GCPのサービスを利用することで堅牢で信頼性の高いGA4 BigQueryのエクスポート通知ソリューションを構築することが可能です。これにより、ダウンストリームジョブは常に安定的に動作し、鮮度の高いデータを利用可能になり、エクスポートが遅延してもチームの時間と意識を無駄にすることなく、本業に集中することができます。