
robots.txt とは、検索エンジンや ChatGPT などのクローラー(Webページを巡回するボット)に対して、自分のウェブページをどのようなルールでクロールして欲しいかを伝えるためのテキストファイルです。
一見シンプルな仕組みであるがゆえに、誤った使い方をされてしまうことも少なくありません。
本コラムでは、 robots.txt のよくある間違い7つをご紹介します。ご自身のサイトが当てはまっていないか、ぜひチェックしてみてください。
- robots.txt をアクセス制限の仕組みと誤解している
- インデックス対象外のページを指定するために robots.txt を使う
- robots.txt をURLの正規化に使用する
- robots.txt でCSS・JavaScriptの読み込みをブロックしている
- User-agent:* をすべてのクローラーに向けた指示と誤解している
- robots.txt に正規表現を使っている
- サブドメイン違いのページを制御しようとしている
- まとめ
robots.txt をアクセス制限の仕組みと誤解している
robots.txt はクローラーによるトラフィックを管理するために使用されるものであり、アクセス制御のためのものではありません。
These rules are not a form of access authorization.
( RFC 9309: Robots Exclusion Protocol, Section 1 Introduction より)
セキュリティ上の理由でクローラーに見られたくないページは次のような手段で制御しましょう。
- アクセス元 IP 制限
- Basic 認証
- ログイン状態でないと見れないようにする
また、robots.txt の指示は各クローラーが自主的に従うものであり、 robots.txt を見ないクローラーも存在します。たとえば ByteDance 社のクローラー Bytespider は robots.txt でブロックしても効果がありません(執筆時点)。
インデックス対象外のページを指定するために robots.txt を使う
原則的に robots.txt が制御するのはクロールであり、インデックスではありません。検索結果に載せたくないページの制御には noindex を使用します。
Google検索では robots.txt でブロックされたページはクロールされなくなりますが、重要なページからリンクされている等の理由でページ内容の確認なしでインデックスされる場合があります。
検索エンジンがページの内容を確認しなくなるので、もしページ内に noindex が設定されていても検索エンジンは気づくことができません。つまり、noindex と robots.txt によるブロックは併用できません。
よく「 robots.txt が無視された」と耳にしますが、これはドキュメントに記載されている仕様通りの結果です。
Googleでは、robots.txt ファイルでブロックされているコンテンツをクロールしたりインデックスに登録したりすることはありませんが、ブロック対象のURLがウェブ上の他の場所からリンクされている場合、そのURLを検出してインデックスに登録する可能性はあります。
(robots.txt の概要とガイド | Google 検索セントラル | Documentation | Google for Developers, robots.txt ファイルの制約について)
Google がページの中身を確認せずにインデックスしたページが検索結果に表示されている様子
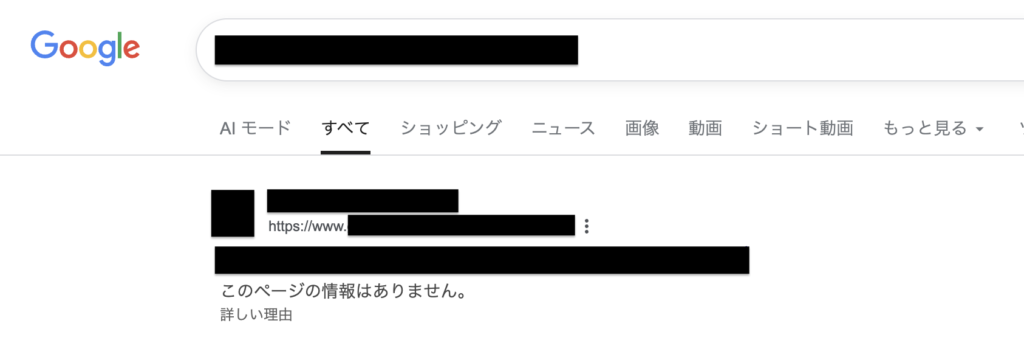
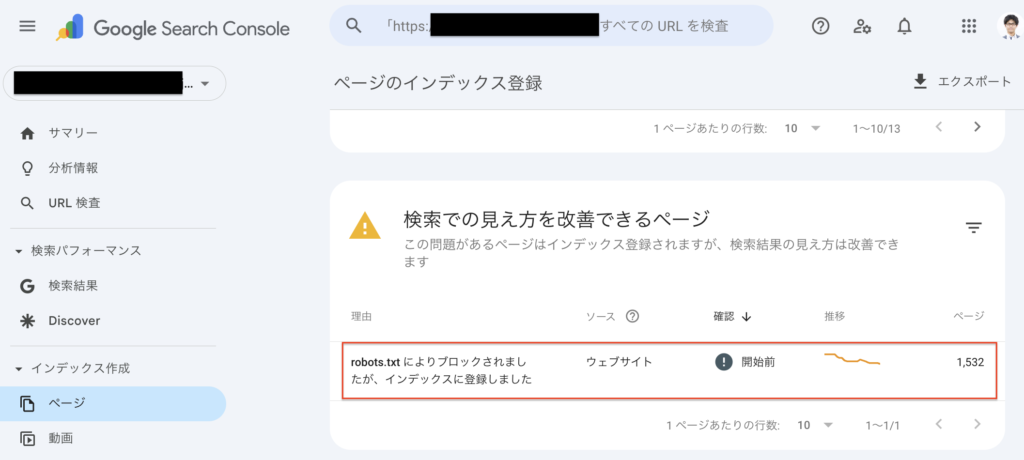
robots.txt でブロックされた状態のままGoogle検索にインデックスされているページは Google Search Console のページレポートでも「robots.txt によりブロックされましたが、インデックスに登録しました」の項目で確認できます。
robots.txt をURLの正規化に使用する
膨大な組み合わせが発生するサイト内検索の絞り込みパラメータ(ファセットナビゲーション)、無限の検索キーワードが発生するサイト内検索結果ページなど、クロールさせる意味がなく、検索エンジンの有限のクロール能力を著しく浪費する可能性があるページを robots.txt でブロックすることには意味があります。
一方で、重複URL問題に対応する目的(URLの正規化)で robots.txt を使うことはできません。URLの正規化を行いたいときは次の何れかの方法で対応します。
- utmパラメータなど、インデックスされたくないパラメータ付きのURLで開かれる可能性があるページ → canonical タグ を使って正規化
- 複数のURLで同じページが表示されるとき(例 : www. の有無・ index.html の有無・ URL末尾のスラッシュの有無) → 301リダイレクトを用いていずれかのURLに統一
また、次のようなページを robots.txt でブロックしてしまった場合、検索エンジンがリンク先ページを発見できなくなったり、リンク元ページとリンク先ページの繋がりを評価することが難しくなったりすることがあります。
- SEO上重要なサイト外リンク・サイト内リンクのURLに含まれるパラメータ
- リンクをクリックしてページが表示されるまでのリダイレクト中に経由するページ
この場合は robots.txt 側でのブロックを避けるか、サイト側のリンクURLやリダイレクト設定を robots.txt でブロックされないものに変更します。
robots.txt でCSS・JavaScriptの読み込みをブロックしている
「クロールによるサーバー負荷を軽くしたい」という目的で、CSS・JavaScriptファイルのクロールを robots.txt でブロックしているサイトを見かけますが、検索エンジンがページの内容を正しく評価することができなくなってしまいます。特別な事情がない限りページの描画に必要なリソースはブロックしないようにしましょう。
Google Search Consoleのライブテストでページの表示が崩れていたり、ページレポートで「ソフト404」が多発している場合、ページの描画に必要なリソースを robots.txt でブロックしている可能性があります。
クロールによるサーバー負荷を軽減したい場合はCDNやキャッシュの活用が有効です。
12 月のクロール情報: HTTP キャッシュ保存 | Google Search Central Blog | Google for Developers
「Google検索結果にCSS・JavaScriptファイルが出てこないようにブロックしている」という話も聞いたことがありますが、これらのファイルはインデックス対象ではないので対策不要です。
Google によるインデックス登録が可能なファイル形式 | Google 検索セントラル | Documentation | Google for Developers
User-agent:* をすべてのクローラーに向けた指示と誤解している
User-agent: * 向けのルールは、個別に指示を受けていない「その他」のクローラーが従うためのルールです。たとえば、次の robots.txt では検索エンジンのクロール能力を浪費するページをブロックするためにDisallowルールが設定されていますが、Bing検索のクローラーである Bingbot に対してはDisallowルールが適用されません。
User-agent: *
Disallow: /search?q=
Disallow: /*?max-price=
Disallow: /*&max-price=
Disallow: /*?min-price=
Disallow: /*&min-price=
User-agent: Bingbot
Crawl-delay: 1
Sitemap: https://example.com/sitemap_index.xmlBingbot 向けには個別に User-agent: Bingbot による指示が行われているため、Bingは User-agent: * 向けのルールを無視します。
robots.txt の文法を定義している RFC9309 にも以下のように書かれています。
If no matching group exists, crawlers MUST obey the group with a user-agent line with the “*” value, if present.
( RFC 9309: Robots Exclusion Protocol, Section 2.2.1. The User-Agent Line より)
先ほどの robots.txt の場合、次の何れかの形に修正することで対応できます。
修正例1: 「その他のクローラー向けの指示」を「 Bingbot とその他のクローラー向けの指示」に変える
下記のような書き方をすれば Bingbot に Disallow ルールと Crawl-delay ルール の両方を見てもらうことが可能です。
User-agent: Bingbot # Bingbotと
User-agent: * # その他のクローラー向けのルール
Disallow: /search?q=
Disallow: /*?max-price=
Disallow: /*&max-price=
Disallow: /*?min-price=
Disallow: /*&min-price=
User-agent: Bingbot # Bingbot向けのルール
Crawl-delay: 1
Sitemap: https://example.com/sitemap_index.xml※ シャープ記号(#)より右側の文字列はコメントとして無視されます
修正例2: Bingbot 向けのルールを削除 & その他のクローラー向けに Crawl-delay ルールを追加
最もシンプルな記述スタイルですが、思わぬクローラーが現在または将来的に Crawl-delay ルールの影響を受けるリスクがあります。たとえばLLMサービスの学習元として多用される Common Crawl の CCBot にも影響します。
User-agent: *
Disallow: /search?q=
Disallow: /*?max-price=
Disallow: /*&max-price=
Disallow: /*?min-price=
Disallow: /*&min-price=
Crawl-delay: 1 # 主にBing向け。Googleには現在非対応
Sitemap: https://example.com/sitemap_index.xml参考までに、執筆時点で次のようなクローラーが Crawl-delay ルールをサポートしています。
- Bing検索 の Bingbot : https://blogs.bing.com/webmaster/August-2009/Crawl-delay-and-the-Bing-crawler,-MSNBot
- Baidu の Baiduspider : https://www.baidu.com/search/robots_jp.html
- Common Crawl の CCBot : https://commoncrawl.org/faq
- Ahrefs の AhrefsBot : https://help.ahrefs.com/en/articles/78158-how-do-i-control-your-bot-s-crawling-behaviour
- Semrush の SemrushBot, SiteAuditBot : https://www.semrush.com/kb/1056-optimize-site-audit-crawl-speed
修正例3: その他のクローラー向けに書いていたルールを Bingbot 向けにもすべて記載する
クローラーごとに細かく指示を分けるときに使いやすい記述スタイルです。 robots.txt の仕様に詳しくない人でも読みやすいですが全体が長くなってしまうため、今後のメンテナンス時に部分的な変更漏れが起きないよう注意が必要になります。
User-agent: Bingbot # Bingbot向けのルール
Disallow: /search?q=
Disallow: /*?max-price=
Disallow: /*&max-price=
Disallow: /*?min-price=
Disallow: /*&min-price=
Crawl-delay: 1
User-agent: * # その他のクローラー向けのルール
Disallow: /search?q=
Disallow: /*?max-price=
Disallow: /*&max-price=
Disallow: /*?min-price=
Disallow: /*&min-price=
Sitemap: https://example.com/sitemap_index.xmlrobots.txt の文法にはグループ化や優先順位など分かりづらいものも多く、記述が増えていくほど思わぬ事故が起こりやすい状態になります。編集前にドキュメントに目を通しておきましょう。
robots.txt に正規表現を使っている
robots.txt のURLパターン指定では JavaScript や Python のような正規表現は使えません。
たとえば、JavaScriptの正規表現であれば「拡張子.pdfで終わるページパス」を /.*\.pdf$ のように表現できますが、 robots.txt の場合、 /*.pdf$ と表現します。似ていますがドット記号とアスタリスク記号の意味が全く異なります。
| 記号 | robots.txt上での意味 |
|---|---|
| . (ドット記号) | 特になし。ただのドット記号 |
| * (アスタリスク記号) | 「ここに何が入ってもOK」という意味 |
| $ (ダラー記号) | URLの末尾 |
詳しくは Googleのドキュメント「Google による robots.txt の指定の解釈」 をご確認ください。
なお、コンピューターの世界で「正規表現」と言うと、一般的に「 JavaScript や Python などで使われている文字列検索や置換のためのパターン記法」を指しますが、形式言語のような学術の世界で言う正規表現は「決められた文字と、連接・選択・繰り返しなどを意味する記号を組み合わせて書き、その意味として『どんな文字列の集まりを表すか』を指定するための式」を指します。
このため学術側の定義に立てば robots.txt で使われる「 * や $ によるURLパターン指定」も正規表現の一種と呼ぶことができますが、 誤解を招き事故を呼ぶのでrobots.txt の文脈では「正規表現」という言葉は避けるようにしましょう。
その他、robots.txt にURLを記述するときは以下にも気をつけましょう。
Allow:,Disallow:の後は/(スラッシュ記号)から記述する(例 :Disallow: /user)- Sitemap: の後は
https://あるいはhttp://から始まるサイトマップファイルのフルURLを記述する - 無関係なページまで巻き込んで Disallow してしまわないように注意する
- URLに複数のAllow, Disallowルールがマッチした場合、ルールが持つURLパターンが最も長いものが採用される(例 :
Disallow: /userなら長さは5) - AllowルールとDisallowルールが両方マッチして、パターン長も同じとき、Allowルールが優先される
サブドメイン違いのページを制御しようとしている
https://example.com/robots.txt に記載されたルールはドメイン・プロトコルが一致する https://example.com のページに対してのみ有効であり、以下のようなページには影響を与えません。
- https://www.example.com/search/?q=t-shirts のようなサブドメイン違いのページ(wwwの有無)
- https://shop.example.com/member/ のようなサブドメイン違いのページ
- http://example.com/aboutus/ のようなプロトコル違いのページ(https・http)
https://www.example.com/search/?q=t-shirts をクロールブロックするためのルールは https://www.example.com/robots.txt のURLで確認できる必要があります。
まとめ
robots.txt はとてもシンプルに見えますが、その役割を取り違えると、次のような問題を引き起こします。
- セキュリティ対策のつもりで書いた設定が、実は何の防御にもなっていない
- インデックスさせたくないページが、URL だけ検索結果に残り続ける
- ページの描画に必要なリソースをブロックしてしまい、クローラーからのページ評価に悪影響が出る
- 正規化やURL統合のつもりの設定が、かえって挙動を複雑にする
実務では、次の点に気をつけることで robots.txt による事故を防ぐことができます。
- Google Search Central の robots.txt ガイド に一通り目を通す
- robots.txt の変更時は robots.txt のテスター や Google Search Console のURL検査ツールで挙動を確認する






