
ChatGPTなどの生成AIが注目されている中で、LLMのクローラー(ボット)の動きも話題になっています。アユダンテのエンジニアの西村とSEOコンサルタントのコガンでアユダンテのサイトのサーバーログで以下の検証をしてみました。
・LLMのボットの動きを確認
・robots.txtで一時的にアクセスをブロックして影響を調査
・ChatGPT、Gemini、Perplexityの引用への影響を調査
今回のサーバーログの分析方法
今回の検証では毎朝サーバーからアクセスログをGoogle CloudにアップしてLooker Studioで見られるようにしました。

この記事ではボットをLLMのボット、リソースタイプをページに絞ってデータを確認していきます。
サーバーログからの気づき
LLMボットの動きで気になった点をいくつか紹介します。
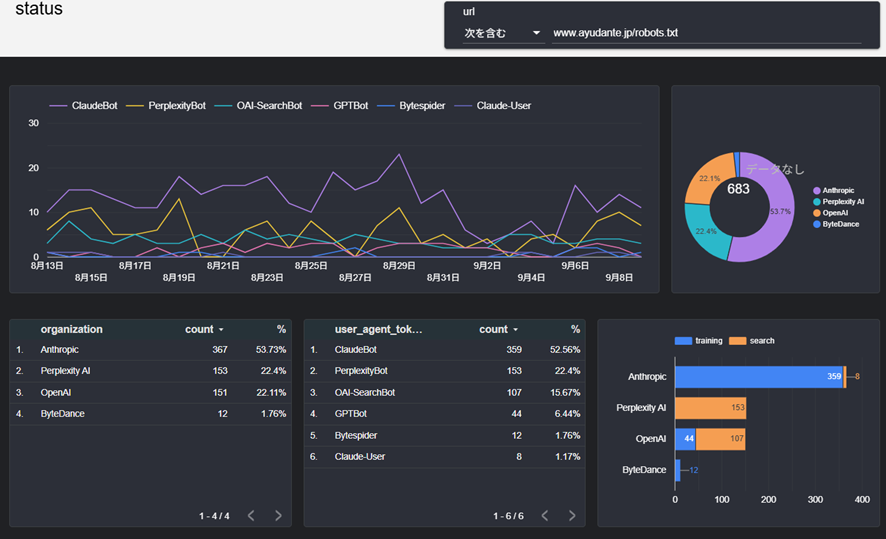
クロール状況の全体像
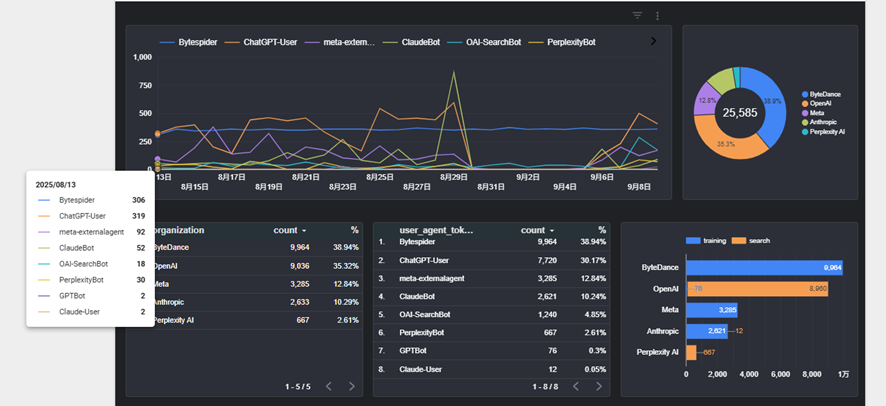
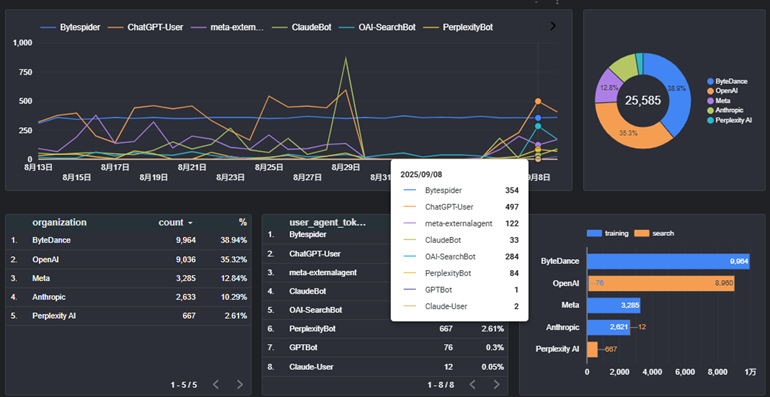
クロール状況の全体像を見てみると、皆さんご存じのようにとにかく中国のByteDance社のBytespiderのアクセスが多いことがわかります。
BytespiderはDoubao等のAI学習用のボットで、アユダンテのような小さなサイトでも毎日定常的300回以上アクセスしてきます。
その次に多かったのは、ChatGPTサーチのリアルタイム検索用のChatGPT-Userですが、週末にアクセスが減少し、平日に増えるというアユダンテサイトの一般的な流入と同じ動きをしています。ユーザーが平日仕事中にChatGPTに問いかけた質問に対してアユダンテサイトが引用されているような動きに見えます。
その次に多いのは学習用のmeta-externalagent(MetaのAIモデル用)と、ClaudeBot(Claude用)でした。
Metaのボットは変動があるものの、コンスタントに毎日100~200回程度来ています。一方、Claudeのボットは毎日数十回来ていたアクセスが8/29にいきなり860回に急増しました。
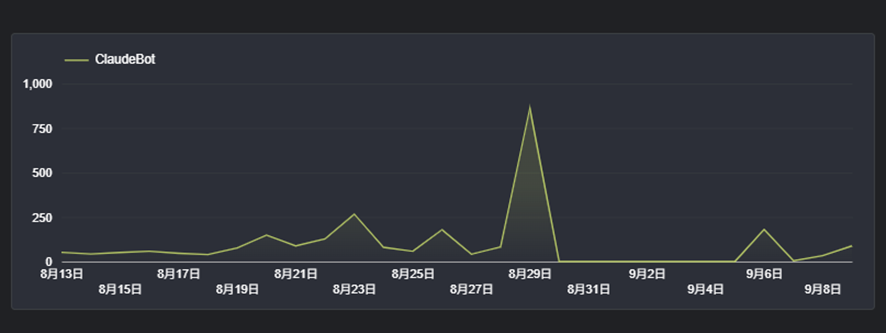
(運悪くその日の午後にLLMのボットをブロックする実験をしてしまったので、860回の急増がその1日だけだったのか次の日も続いたのか確認できませんでした)。
クロール数が増加した8/29はrobots.txtの調整以外、アユダンテのリリース等も特になく、Claudeがクロールしたページを確認してもどこか特定のページ群を訪れたわけではなく、サイト全体を一通りクロールしていました。突然何を収集していたのか特殊な動きで気になりますので、Claudeはこれからもモニタリングしていきたいと思います。
5番目に多かったのはOAI-SearchBot、ChatGPTの検索機能のためにWebを定期的に巡回し、インデックスを作成するボットでした。ChatGPT-Userとは違って平日と土日での浮き沈みがなく、定期的にクロールして検索用に情報を収集しているようです。このボットの動きについてはまた後程触れていきます。
Geminiのボットは?と気になる方がいるかもしれませんが、Geminiの場合、Robots.txtのブロックでは「Google-Extended」に対しての指示に従いますが、実際にGoogle-Extendedを含むUser-Agent文字列でサイトにアクセスが発生する訳ではないようで、LLM用のクロールも既存のGoogleユーザーエージェント文字列で行われているようです。そのため、今回Gemini用だけのクロールを特定していません。
参考:Google の一般的なクローラーの一覧:Google-Extended
学習用と検索用ボットの動きの違い
生成AIのクローラーには学習用とリアルタイムの検索用(RAG)の2種類のボットが存在することが多いです。そこで、ボットを学習用と検索用で分けて、どのページにアクセスしているか確認してみました。
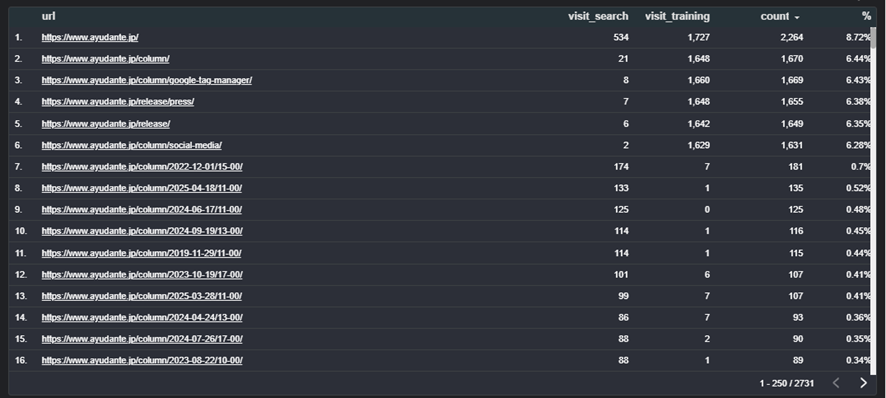
学習用→メニューからリンクされているや、永続的なページへのアクセスが多い
検索用→トップ、コラム記事へのアクセスが圧倒的に多い
上記のキャプチャーはBytespiderのデータを含むため多少のデータの偏りはありますが、Bytespiderを除外してもすべてのボットで同様の傾向でした。
(Bytespiderはアユダンテのコラムの中でSNSカテゴリだけをなぜか定期的にクロールしていました。)
Bytespider以外のすべての学習用ボットの他の共通点は2012年-2016年度の非常に古い記事やプレスリリースへのアクセスが多かった点で、逆に最新の記事はさほどアクセスされていませんでした(アユダンテはURL内の年号で公開日を確認できます)。
以下学習用ボットのアクセス数順でURLを並べましたが、visit_searchという検索用ボットのアクセス数と比較して見ると、検索用ボットはあまり訪れていないページだとわかります。
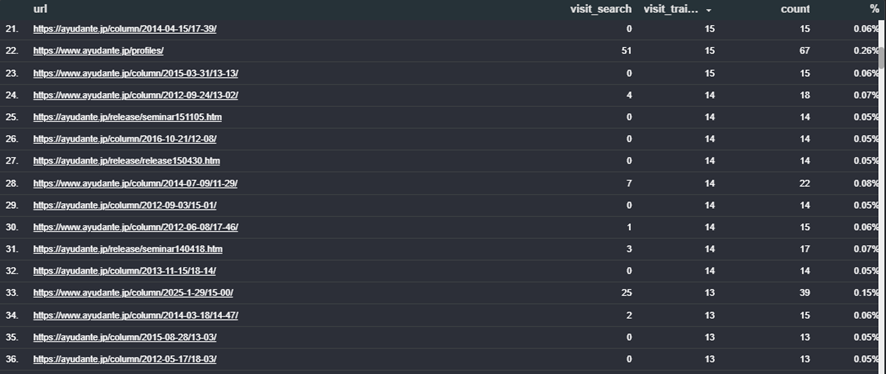
検索用ボットは数年以内の比較的最近の記事を見に来ています。以下は検索用ボットのアクセス数順で並べたURLですが、今度は逆にvisit_trainingという学習用ボットの数値を見るとそちらのボットはあまり来ていないことが分かります。
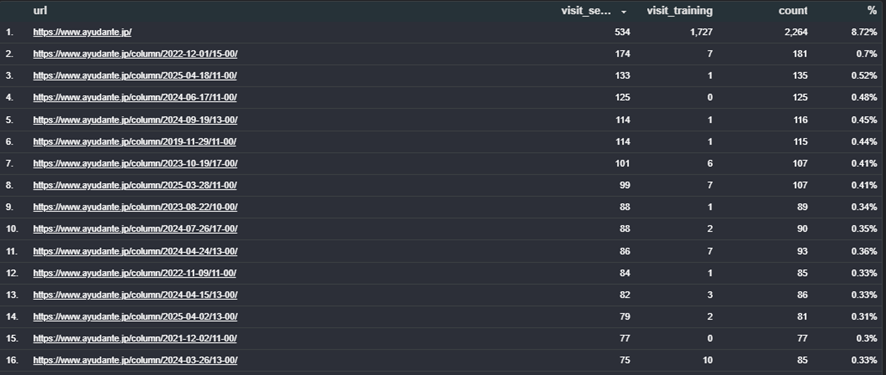
比較的最近のものが検索に引用されるのは想定内ですが、古い記事がサイトの主要なページと同じように学習に使われるのは意外でした。安定した、変更が少ないという観点から古い記事が学習に使われているかもしれませんが、情報が古い記事が学習に使われるとデメリットも懸念されます。あまりにも古い、現状あまりユーザーに役に立たないコンテンツはWebへの貢献も考慮して残し続けるのではなく、削除していっても良いのではないかと思いました。
llms.txtへのアクセスが全く見られない
llms.txtとは、AI向けのウェブサイトの概要をLLMに読みやすい形で伝えるファイルです。2024年から利用が提案されて推奨している専門家がいる一方、主要なLLMがサポートを表明しているわけでもなく、「要らない」という意見の専門家も多いです。
アユダンテのサイトではllms.txtを設定しているわけではないですが、robots.txt同様設定しているかどうかに関わらず、サポートしているボットであれば一度はhttps://ayudante.jp/llms.txtへのアクセスはあるはずと仮説していました。
ただし、どのボットもhttps://ayudante.jp/llms.txtへのアクセスを確認できませんでした。
今後ファイルを作ってアクセスを促してみようとは思いますが、やはりLLMがllms.txtを積極的に使っているようには見えません。
LLMボットをrobots.txtでブロックした考察
LLMのボットをrobots.txtでブロックしてそのアクセスとLLMの回答内容の変化について確認してみました。
最近CDNを提供しているCloudflare社が生成AIのPerplexityに対してrobots.txtのブロック指示を無視して、UAやIPを変えてクロールし続けていると断言して、LLMのRobots.txtに対しての反応が話題になっています。
参考:Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives (英語)
アユダンテのサイトでもLLMのボットをrobots.txtでdisallowした際に、すべてのボットが指示に従うか、またLLMのプロンプトに対してサイトが引用され続けるか、引用されなくなるかの検証をしてみました。
robots.txtの設定に対してボットのアクセス状況
最初にボットがrobots.txtでdisallow設定にどう反応しているか見てみました。
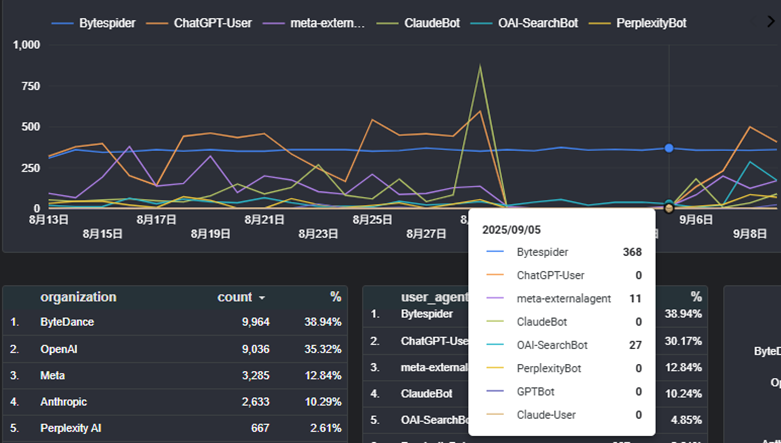
8/28の夕方にアユダンテのサイトに来ているLLMボットのユーザーエージェントに対してrobots.txtに以下のようなdisallowの記載をしました。そして一週間後の9/5の夕方に指示を消しました。
ボットのアクセス状況を確認すると、ほとんどのボットがrobots.txtでブロックされた期間にアユダンテのウェブサイトにはアクセスしていません。つまり、指示には従っているようです。
robots.txtの認識に多少のタイムラグが発生する場合があるようで、meta-externalagentとGPTBotについては8/30にも少しだけアクセスがありましたが9/1以降にはしっかりアクセスを止めているようです。
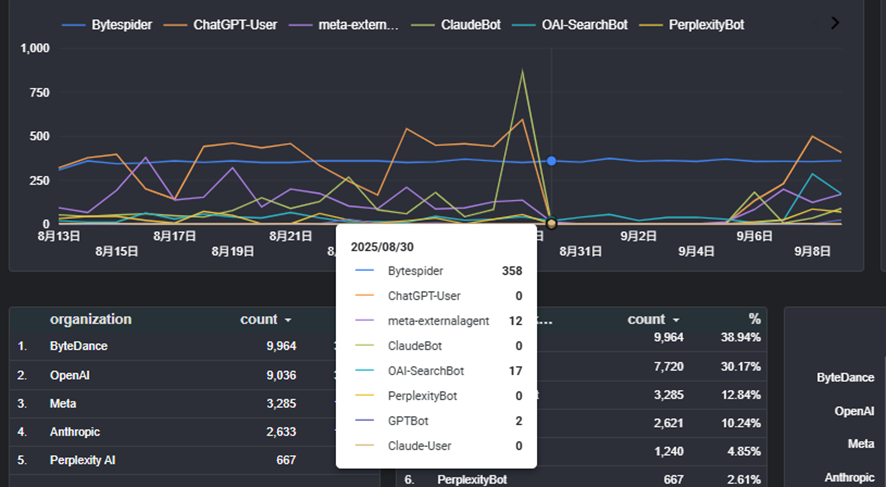
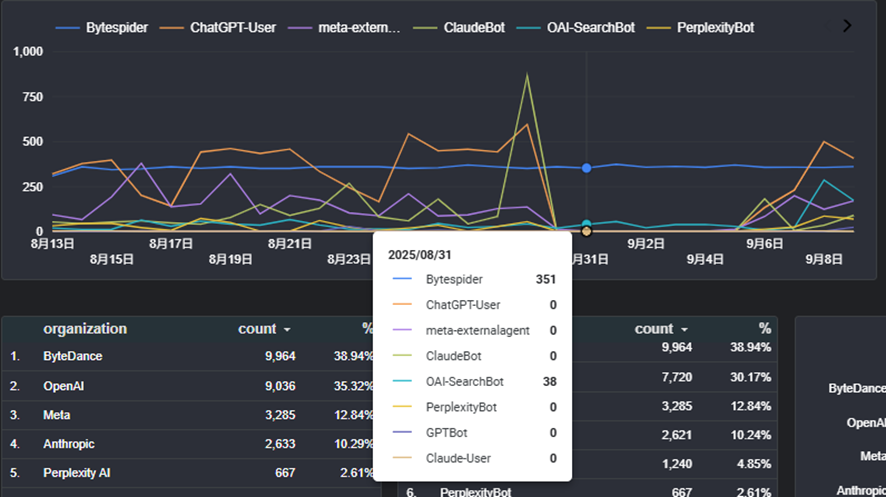
一方、Bytespiderはrobots.txtを無視するので、変わらず毎日数百回クロールしてきていました。IPでの除外もできないようで、なかなかややこしいクローラーです。
意外だったのは、OAI-SearchBotもクロールし続けていたことです。公開資料では、タイムラグの可能性はあるもののrobots.txtの指示には従うと明記していますので、OpenAI側のバグでしょうか。
逆に話題になっていたPerplexityは、robots.txtに従って公開UAでのクロールを止めています。アユダンテ全体のボットのアクセス数を見てもPerplexityのアクセス数は非常に少ないので、違うUAに成りすましてクロールしてもわからず、Cloudflareが言っていたようにUAを変えてクロールし続けているかどうかは今回判断できませんでした。
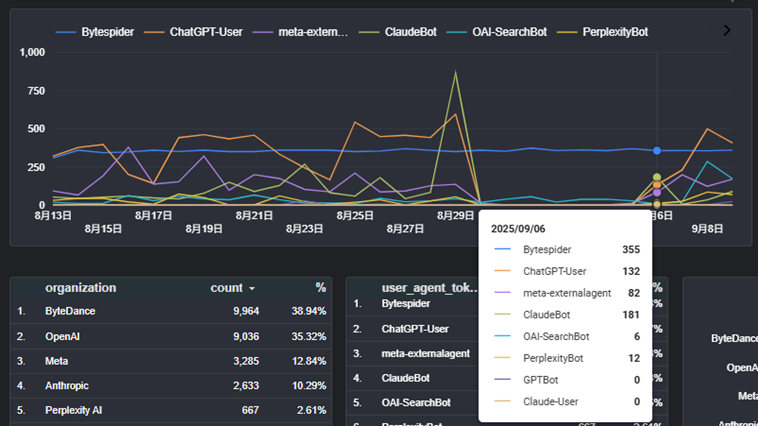
robots.txtのファイル自体には、各社のボットはブロック期間中毎日アクセスしていて(Bytespiderのみ元々数日ごとしか来ていない)、クロールして良いのかどうかを確認していたようです。
クロール再開については、meta-externalagentだけブロック解除当日すぐに戻ってきて、その他のほとんどのボットは次の日からアクセスを再開しています。Claudeはブロック解除2日後の9/7から、GPTBotはブロック解除3日後の9/8にアクセスを再開してました。元々アクセス頻度が高くないのでたまたまだったか、タイムラグがやや長かったです。
robots.txtでブロックした前後の生成AIでの引用状況
robots.txtでブロックした前後で各生成AIでの引用状況に変化が出るかChatGPT(様々なモデル)、Gemini(2つのモデル)、またPerplexityで検証をしてみました。
送信プロンプト
- アユダンテ株式会社について教えて
- アユダンテが提供しているサービスの概要を教えて
- アユダンテの西村彰悟について教えて
- コガンポリーナについて教えて
- この記事について教えて:https://ayudante.jp/column/2025-09-01/13-00/ (記事公開後)
- この記事について教えて:https://ayudante.jp/column/2022-12-01/15-00/
検証タイムライン
- 8/29昼にプロンプト送信
- 8/29夕方 robots.txtでのブロック開始
- ブロック直後にプロンプト送信
- 9/1数日経過後にプロンプト送信
- 9/5夕方 robts.txtのブロック解除
- 直後、数時間後、数日後にプロンプト送信
プロンプトについてはコガンと西村で生成結果が異なったり、実行するタイミングによって異なったり変動があるため今回の少ない検証数では明確な結論が出ませんでした。以下にアユダンテのサイトの引用状況だけまとめます。
検証結果
| LLM/モデル | ブロック前 | ブロック直後 | ブロック数日後 | ブロック解除直後/数時間後 | ブロック解除数日後 | 引用復活のタイミング |
|---|---|---|---|---|---|---|
| ChatGPT5 Auto | 引用されていた | 引用されていた | 引用されていなかった | 引用されていなかった | 引用されていた | ブロック解除の翌日 |
| ChatGPT5 Instant | 引用されていた | 引用されていた | 引用されていなかった | 引用されていなかった | 引用されていた | ブロック解除の翌日 |
| ChatGPT5 Thinking | 引用されていた | 引用されていた | 引用されていなかった | 引用されていなかった | 引用されていた | ブロック解除の翌日 |
| ChatGPT5 Pro | 引用されていた | 引用されていた | 引用されていなかった | 引用されていなかった | 引用されていた | ブロック解除の翌日 |
| Gemini 2.5 Flash | 引用されていた | 引用されていた | 引用されていなかった | 引用されていなかった | 引用されていた | ブロック解除の翌々日 |
| Gemini 2.5 Pro | 引用されていた | 引用されていた | 引用されていなかった | 引用されていなかった | 引用されていた | ブロック解除の翌々日 |
| Perplexity | 引用されていた | 引用されていた | 引用されていなかった | 引用されていなかった | 引用されていた | ブロック解除の翌日 |
結論、すべての生成AIはrobots.txtの指示に従っており、Perplexityもブロック後はアユダンテのサイトを引用しなくなっていました。
Perplexityのブロック前後の例
| ブロック前 | ブロック後 |
| アユダンテ株式会社は、主にSEO施策を中心としたデジタルマーケティング支援を行う企業です。[1][2][3] 事業内容 SEOコンサルティングやウェブマーケティング、サイトリニューアル、検索ニーズ調査、コンテンツ作成支援などを提供しています。[3][4][1] 運用型広告やGoogleマーケティングプラットフォーム導入支援、モバイル・ウェブ向けソフトウェア開発も行っています。[5][3] 独自開発ツール「Quick DMP」やTwitterクライアント「つぶやきデスク」などの自社サービスも展開しています。[5][3] 会社情報・特徴 設立は2006年2月28日で、東京都千代田区麹町に本社があります。[6][7][3] 代表取締役は安川洋氏です。[7][6][3] 社員数は約60人(規模は拡大傾向)で、最新では51-200人の規模とされています。[3][5] 創業以来、黒字経営を継続しており、少数精鋭でありながら業界で高い評価を受けています。[4] 経営方針・社風 「ユーザー中心」の考え方を重視しており、技術者とコンサルタントが協力し合う文化があります。[2][8][7] 社員の幸せを企業理念の中心に据え、女性や家庭との両立を支援する就労制度、充実した学びのための社内勉強会や書籍代・セミナー費用の全額負担など福利厚生が整っています。[9][4] 得意分野・実績 オーガニック検索に強みを持ち、SEO戦略やデジタル広告、Google Analyticsの導入コンサルティングでも業界をリードしています。[5][3] 大手企業から中小まで幅広く支援しており、専門家アドバイザー陣による高品質なサービスが特徴です。[8][6] アユダンテ株式会社は、SEOとデジタルマーケティング領域で長年の実績を持つ、技術力とコンサルティング力が両立した日本有数の企業です。[1][6][3][5] ⁂ https://www.nikkei.com/compass/company/1PSF4VDTXLEWEqfHZNTfWq https://ayudante.jp https://www.green-japan.com/company/9226 https://ayudante.jp/info/recruiting/ https://jp.linkedin.com/company/ayudante-inc- https://ayudante.jp/info/company/ https://ayudante.jp/info/ https://www.green-japan.com/company/9226/interview https://en-hyouban.com/company/10093760356/ https://x.com/ayudante | アユダンテ株式会社は、東京都千代田区に本社を持つ、SEOコンサルティングやデジタルマーケティング支援サービスを中心とした企業です。[1][2][3] 事業内容 SEO対策やウェブマーケティングコンサルティングを主力としており、Googleマーケティングプラットフォームの導入コンサル、運用型広告支援、コンテンツ開発支援なども行っています。[3][1] 独自のソフトウェアも展開しており、「つぶやきデスク」(Twitterクライアント)や「Quick DMP」(データ可視化ツール)などのサービスも提供しています。[3] 創業背景・特徴 IT業界で要職を歴任した代表が、技術力重視のデジタルマーケティング会社として2006年に創業しました。[4][3] 社員の自律性や成長を重視し、「社員の幸せ」が会社の根本理念とされています。自由な働き方や個々の成長、プロアクティブな行動を奨励しています。[5][4] 福利厚生・働く環境 リモートワークやスーパーフレックス勤務が可能で、敷金・礼金・仲介手数料会社負担、住宅費の給与天引き対応など独自の福利厚生があります。[5] テスラ無料レンタルなどユニークな福利厚生も導入されています。[5] 社員数は約60名、退職者も少なく、働く環境の満足度も高めです。[3][5] 文化・採用 コンサルタントの担当顧客数を少数に絞り、質を保つ方針です。[3] 国籍・年齢・性別・学歴問わず採用しており、自律性・独立性が重視されています。[4] SEOやデジタルマーケティング支援で実績と信頼を有し、社員成長・働きやすさを重視するテック企業です。[2][1][4][5][3] ⁂ https://www.nikkei.com/compass/company/1PSF4VDTXLEWEqfHZNTfWq https://x.com/ayudante https://www.green-japan.com/company/9226 https://www.green-japan.com/company/9226/interview https://en-hyouban.com/company/10093760356/ |
興味深いと思った点
検証を通じて興味深いと思った点は以下3つです。
- ブロック直後、数時間後もサイトが引用され続けていました。逆にブロック解除直後や数時間後でもサイトが引用されなかったり、場合によってはrobots.txtでアクセスが制限され、アクセスできないという回答が出ていました。この結果から、LLMがプロンプトを受ける度にサイトにアクセスしていいかどうかリアルタイムで確認してアクセスするわけではなく、ある程度のキャッシュを持って利用していることが想定できます。
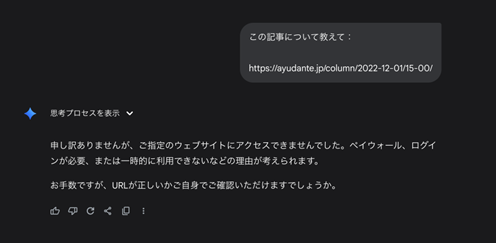
※キャッシュがユーザー単位なのか、LLM自身が覚えているのか気になりましたので今後検証できたらと思います。 - 検索用ボットが良く来ている記事「https://ayudante.jp/column/2022-12-01/15-00/」についてのプロンプトを送信しても、以下Gemini 2.5 Flashの結果の例ように、インデックスから記事についての情報を出すのではなく、「robots.txtによってブロックされているため、アクセスできません」というような回答しか出てきませんでした。
- クローリング能力等を考えるとGeminiが一番早く引用再開することを想定していましたが、引用再開のタイムラグはGeminiが一番長かったです。
robots.txtの除外解除は9/5の夕方に行い、ChatGPTとPerplexityの引用は9/6の夜に確認できたものの、その時点でGeminiの引用はまだ復活せず、9/7の昼頃にやっと引用を確認できました。細かい時間の確認まではしていないですし、タイムラグの変動もある可能性も高いですが、Geminiはブロック解除してもすぐにはサイトを引用しないという点だけ把握しておこうと思います。
LLMからの流入状況の変化
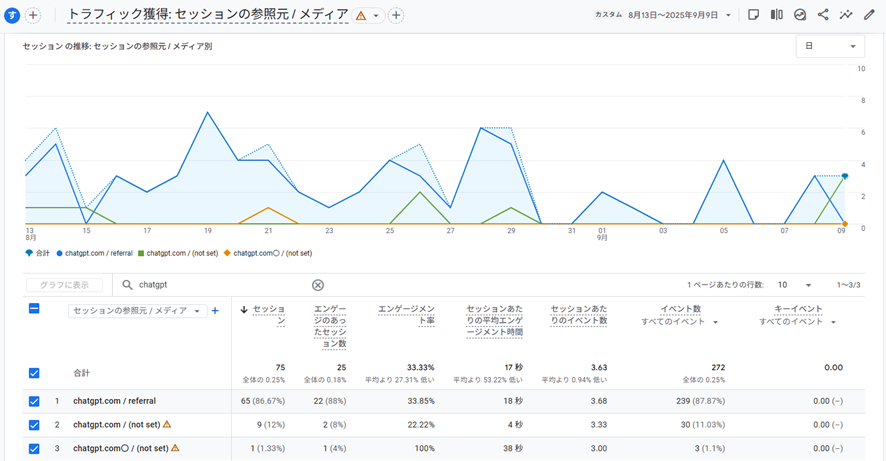
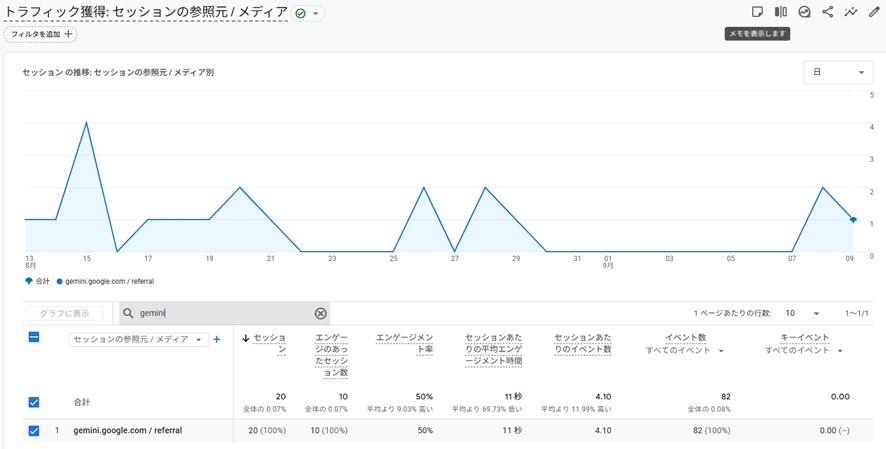
生成AIからの流入状況はGoogle アナリティクスでわかります。今回の検証でも流入の変化を確認してみました。生成AIからの流入はどのサイトも1%に満たないというデータも弊社では得ており(弊社顧客の平均)、アユダンテサイトでもその流入数は非常に少ないです。ChatGPT、Gemini、Perplexityともにrobots.txtが設置されていた8/30-9/4の期間はほとんど流入は発生していません(やはり今回の検証ではPerplexityがUAを変えてアクセスし続けていた可能性は極めて低いと考えて良いでしょう)。
ChatGPTのみ、9/1と9/2に2023年~2025年の3つの記事に3件の訪問が見受けられましたが、過去の回答からの流入や、過去にChatGPT経由で流入して次に直接サイトにアクセスしたユーザーの元の参照元情報が引き継がれている可能性が高いと思います。
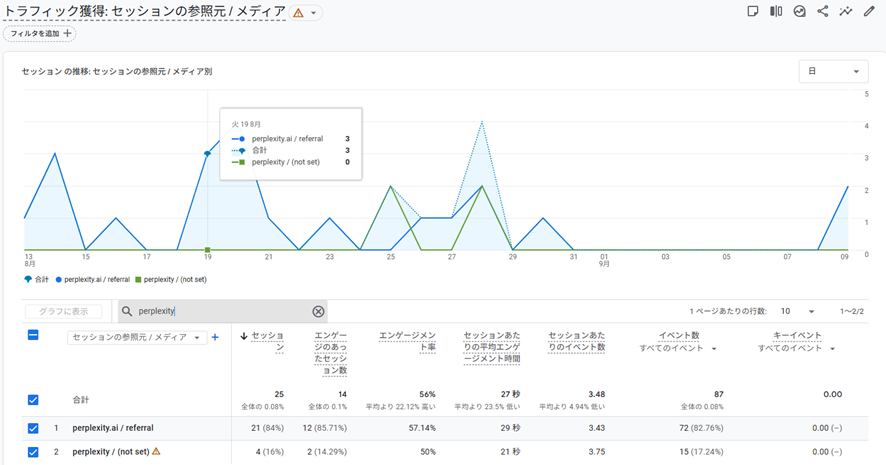
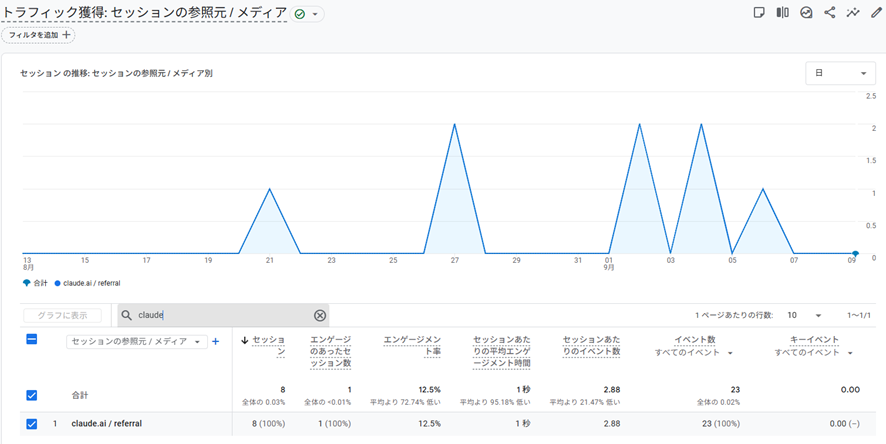
また、アユダンテへの流入が少ないのであまり気にしていなかったClaudeが、ブロック期間中も流入していましたのでClaudeはやはり今後も検証してみたいと思います。
まとめ
今回の検証から、LLMボットのクロールや引用には以下の特徴が見られました。
- 学習用と検索用で挙動が異なる:学習用は安定した古い記事や恒常的なページを、検索用は直近の記事を重点的にクロール。
- robots.txtの効果は限定的:多くのボットは指示に従うが、Bytespiderのように無視するものや、OAI-SearchBotのように想定外の挙動が見られるケースもあった。
- 引用にはキャッシュ又はシステム固有の遅延が影響:ブロックや解除の直後には反映されず、数時間〜数日単位のタイムラグがあり、更にタイムラグはLLMによって差がある。
総じて、LLMボットはrobots.txtを参照しながらも完全には制御できず、さらに引用結果にはキャッシュやモデルごとの特性が大きく関わっているように見受けられました。今後も観測を続けて、ボットの挙動や実際のサイトへの影響を継続的に把握していければと思います。
生成AIの対策が気になる方はぜひ生ログでのクローラー分析も行ってみてください。打ち手へのヒントになるかと思います。










