2024年5月末にGoogleの社内文書が漏洩したニュースは、SEO業界で恐らく今年最大のニュースとなるでしょう。最近オンラインで開催された検索エンジンマーケティングに特化したカンファレンス「SMX Advanced」でも、この話題で持ちきりでした。ただこの漏洩文書は誤って読み解いてしまう可能性も十分あるため、私たちは原文ソースも確認しながら社内で理解を深めてきました。どんな内容が漏洩したのか、紹介する記事はたくさんあると思いますので、この記事ではアユダンテの観点で興味深く感じた5つの項目について深く解説します。※この記事の情報は英語圏含めた6/28時点での最新情報となります。
漏洩したGoogleのドキュメントとは?
まず、一体何が漏洩したのでしょうか?一説にはGoogle検索のランキングアルゴリズムやソースコードが漏洩したとも言われたりしていますが、実際にはGoogle CloudのDocument AI Warehouseというサービスから、「Content Warehouse」APIというGoogleの内部文書が流出しました。
漏洩したドキュメントには、2,596のモジュールと14,014の属性が記載されています。Google検索だけでなく、Googleアシスタントやマップなど他のサービスに関する情報もありました。ただし、多くのモジュールは検索結果を生成する際に使用される「Protocol Buffers」と関係があるようで、約8,000の属性がGoogle検索に関連しており、SEO業界において非常に価値のある情報ではないかと思います。
今回の文書から、Googleが保存しているデータやデータの粒度などは明らかになりましたが、一方でデータが実際にどう使われているかや、各要素の重み付けについてはわかっていない点が要注意ポイントです。文書の内容を鵜呑みにせず、慎重に見ていく必要があると考えます。
さて、漏洩した情報は膨大ですが、この記事では筆者が気になる5つの項目を取り上げ、次から詳細に解説したいと思います。
1.Navboost(最重要):SEOにUXが重要との裏付けがとれた!
去年、米国司法省対Googleの裁判が話題になりました。その中でNavboostも話題になりましたのでご存じの方もいるかもしれません。これは、Googleが検索結果からのクリックデータの13ヶ月分を分析してランキングを調整するシステムであり、最も重要なランキングシグナルの一つと言われています。例えば、Googleは各クエリでの順位とCTRデータを持っているようです。
例:

「SEO会社 東京」でアユダンテが4位だとして、そのCTRが10%を大きく超えていればそのクエリでのアユダンテの順位が上がることがあるというものです。
もちろん、CTRだけで決まるわけではありません。リークされたドキュメントの中でも、Navboost関連のモジュールの配下に「goodClicks」、「badClicks」、「lastLongestClicks」、「unsquashedClicks」など多種多様なクリックデータが収集されていることが明らかになりました。

その中で、「lastLongestClicks」という「滞在時間」に類似した、セッション中にどの結果が最も長くクリックされたかのデータはSEOエキスパートたちの間で注目されています。また、「unsquashedClicks」の定義は記載されていませんが、クリックデータが不正操作されていないことを確認するための指標だとテクニカルSEOの専門家Mike King氏が推測しています。どちらにしてもGoogleは検索結果からのクリックやその質を見てそれをランキングに使っていることがうかがえます。
せっかく自社のページに訪れたのにすぐ検索結果に戻って別のページをクリックすることは恐らく「badClicks」、悪いクリックに該当しますので、ランディングしたページの質や使いやすさ(UX)の重要性がうかがえますね。
そして、もう1つ、今回の漏洩でGoogleがChromeのユーザー行動データを使っていることもわかり、それも大きな話題となっています(ページエクスペリエンスシグナルのランキング要素に使用されていることは既に公表済み)。Chrome関連の属性が文書にはいくつか登場しています。恐らくGoogleはサイト内のユーザーの行動も分析しているでしょう。
例①

例②

例③
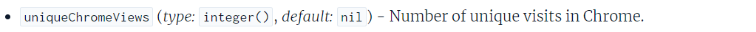
【SEO担当者へのアドバイス】
- ユーザーがランディングしたページのSEOとUXを両立させ、ページを見て満足してもらうこと、再度検索結果に戻らないことや、長く滞在するセッションを増やすことが大事です。
- そのためにはユーザーの検索クエリときちんと関連のある良質なコンテンツを作ること、回遊できるためのわかりやすいナビゲーションなどが重要でしょう。
- CTRやクリックデータの売買サービスがあるようですが(特に海外)、Googleは不正操作のパターンをみていますので持続的な効果はないと思います。
- ヒートマップやSimilarWebなどのツールを活用し、ユーザー行動を良くすると良いでしょう。

最近はこのリークの件で、大量のユーザーがRand氏のサイトからMike King氏のサイトiPullrankへ遷移したことがうかがえます
2.エンベディングとベクトル検索について理解を深めよう
エンべディング(Embedding)という概念はあまり日本では耳慣れない言葉ですが、今回のドキュメントに頻繁に出てきますので、紹介します。少し難しい解説ですが、エンベディングとベクトル検索はこれからのSEOでは知っておいたほうがいい情報です。
これまでのウェブ検索はキーワードをスペースで区切って処理していましたが、今はセマンティック検索(Semantic Search)*も利用されるようになっています。*セマンティック検索とは、検索エンジンがテキスト、画像、音声の形態を問わず、「検索クエリ」の意味を理解し、「検索クエリ」と内容が近い検索結果を出力する技術。

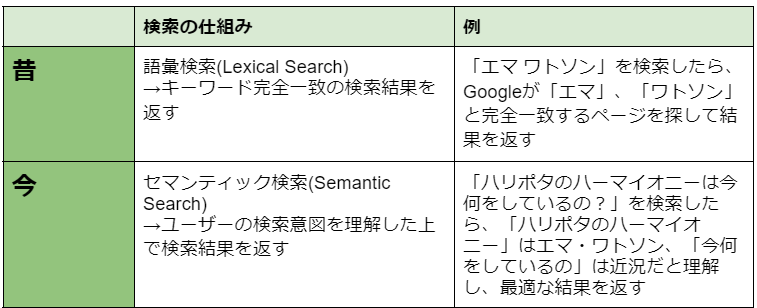
セマンティック検索の裏側には2つの技術があります。
- エンベディング
- ベクトル検索
まずエンベディングについて説明します。
エンべディングとは、ユーザーが検索した文字列をベクトル(向きと大きさの2つの量を持った矢印、見た目は数字の羅列)に変換することです。例えば、ねこは文字のままではなく、「0.1,0.002,0.56」になります。また、文字列だけではなく、画像や音声もエンベディングできます。
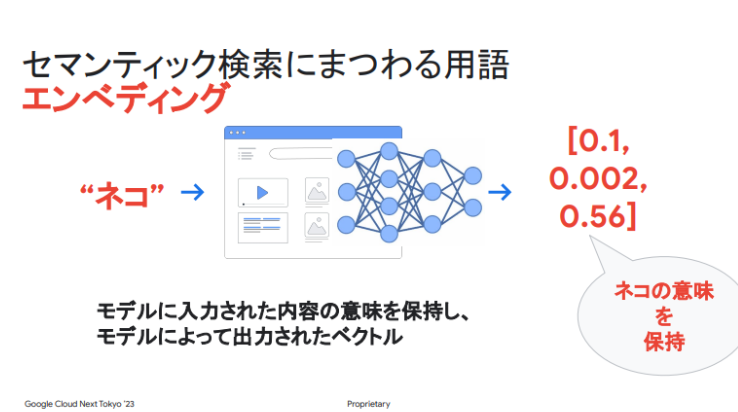
エンべディングをする目的は、ベクトル化されたデータ間の距離を計算して関連度を判定し、より関連度が高い検索結果を表示することです。これがエンベディングと同じくセマンティック検索の裏側にある2つ目の技術「ベクトル検索」です。
「ベクトル検索」は検索エンジンだけではなく、サイト内検索でも活躍しているようです。例えば、ECサイトで「ネコ柄のTシャツ」を検索したら、今までは商品名に「ネコ柄のTシャツ」と書いていない商品はヒットさせることができなかったのですが、画像もエンベディング化することで、商品名に「ネコ柄」と入っていないTシャツもヒットできるようになりました。ユーザーにとってはありがたい機能ですよね。
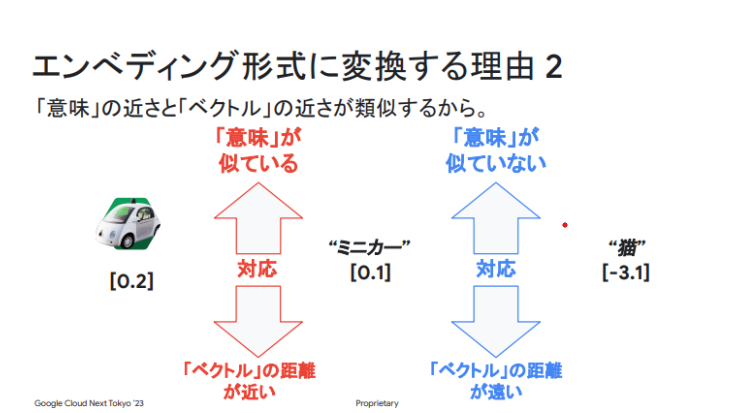
つまり、Googleの今の検索「セマンティック検索」はエンベディングとベクトル検索によって実現されているのですが、リークされたドキュメントからも、Googleがページレベル、サイトレベル、エンティティレベル、トピックレベルなど、様々な粒度のベクトル間の関連度を測定していることがわかりました。

【SEO担当者へのアドバイス】
- Googleはページの内容とサイト全体のテーマの関連度を計測しているので、コンテンツのテーマの幅は広げすぎないほうが良いです。
- 新しいトピックで記事を公開したい場合は、トピックオーソリティを獲得できる十分な量の記事を用意するか、その分野の専門家が執筆することが重要な要件です。
- Googleはすべてのページの更新履歴(前後全ての情報)を保持しており、評価には最近更新された20バージョンを見ているようです。更新前後のバージョンがエンべディングされ、比較することもできるようですので、中身に大幅な変更がなければ、ページの日付を変更しても更新したとは見なされないようです。よく記事を微調整して日付を最新に更新するケースがあると思いますが、気を付けましょう。

3.リンク:リンクには3つの質がある?!
次は、この文書が漏洩してからSEOの専門家たちがよく取り上げている属性の一つ「sourceType」について説明します。「sourceType」はリンクに関する属性のようです。

上記の説明文によると、アンカー(リンクのこと)の品質は次の3階層に分かれているようです。
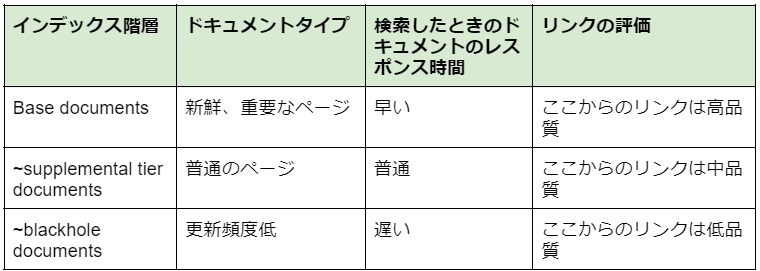
Googleは流入数に基づいてページを上記3つのインデックス階層に振り分けているようです。
例:
ページA:流入数1 →blackhole documentに振り分ける
ページB:流入数1000 →base documentに振り分ける
つまり、流入の多いページBはbase documentに振り分けられ、そこからのリンクは質が高いということになります。これは、例えばトップページからのリンクの価値は非常に高いという弊社のSEOの経験に一致しています。
また、このリンクは外部リンクと内部リンク両方の可能性があります(先日のMike King氏のウェビナーで筆者が確認)。
【SEO担当者へのアドバイス】
- 内部リンクはTOPページなど流入の多い上層ページからしっかり設置するとよいです。
- 被リンクの獲得には、数よりも高品質のリンクを重視すると良いです。
- リンク元とリンク先のページの関連度が低い場合は、被リンクが無視される可能性があるので注意が必要です。
- local anchor関連の属性を見ると内部リンクにキーワードのアンカーテキストを置くことは問題なく、効果的であることをMike King氏が推測しています。(外部リンクはキーワードリンクはスパムの可能性があるが、内部リンクはその懸念がないので)
4.記事作成時に注意、エンティティとナレッジグラフ
もともと検索エンジンは、自然文や音声などの非構造化データを読み取ることができません。そのため、機械が理解できる形式で、エンティティ(人名、物、場所など物事の最小単位)とエンティティ間の関係性を示すモデルが作られました。これがナレッジグラフです。
ナレッジグラフには、公開のプロジェクトと企業向けのものがあります。前者の代表例はWikidataであり、後者はGoogleやAmazonなどの大企業が利用しています。ナレッジグラフの活用事例も様々で、Googleのナレッジパネルが最も有名ですが、Netflixのおすすめ機能やInstagramの広告配信などにも活用されています。
ナレッジグラフについては今まであまり技術面での解説がなかったように思いますが、今回の文章の中で技術的な記載もあったので取り上げてみたいと思います。
漏洩したドキュメントによると、GoogleはSAFT (Structured Annotation Framework and Toolkit)という仕組みを使って文章を読み取り、そこからエンティティとエンティティ間の関係性を抽出し、タグをつけています。
そして、以下のモジュールが今回漏洩したエンティティに関するものの例です。

以下に興味深いモジュールと属性をいくつか記載します。
・type(属性):エンティティの種類。種類にはSAFTタイプ(/saft/location, /saft/art, /saft/other/living_thingなど)やコレクションタイプ(/collection/tv_personalities, /collection/statistical_regions)などがある。
・NlpSemanticParsingSaftCoreference(モジュール):代名詞やメンションからエンティティを判断している。
・identifier(属性):関係性を説明する外部の識別子。
・embedding(属性):エンティティをベクトル空間にエンべディングする。
【SEO担当者へのアドバイス】
- Googleは著者情報とナレッジグラフのエンティティ情報の関連度を計測しているため、記事の著者や監修者は、経験の浅い複数のフリーランスよりも、他のメディアで執筆経験があり、認知度の高い専門家が望ましいです。
- メインコンテンツ(MC)から最初の400文字を、エンティティを認識するために使っているようですので、重要な内容は最初に置いておきましょう。
※補足:メインコンテンツについてはGoogleの検索品質評価ガイドラインに出ています。
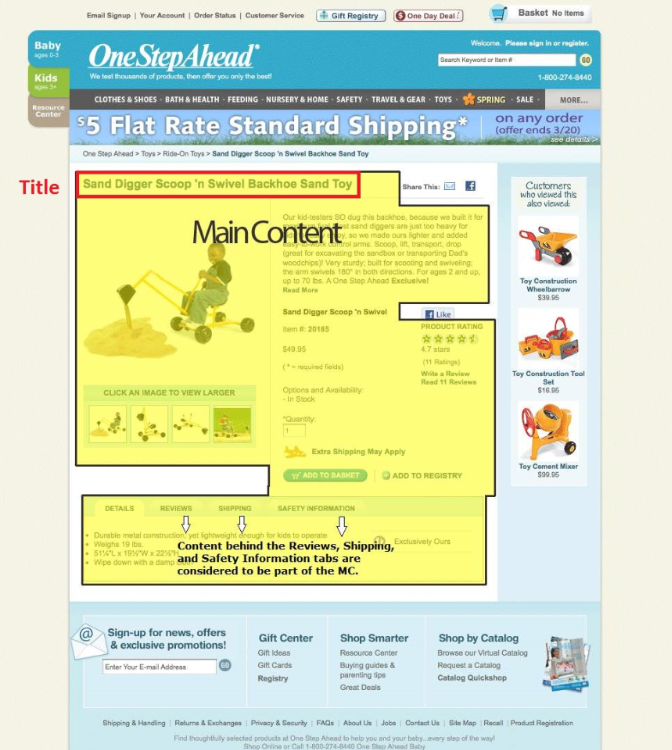
- リッチリザルトのために構造化データを使用するケースが多いですが、ビジネスにおいて重要なエンティティはすべて構造化データでマークアップすべきです。コンテンツやその内容をよりGoogleに伝えることができるでしょう。
※上記は今年4月のSearch Engine Journalに掲載された記事で構造化データの専門家Martha van Berkel氏が推奨。Martha氏は数理工学科出身なので、AIにおけるナレッジグラフの役割やSAFTの仕組みをよく理解した上で提案していたのだと考えます。
5. 検索結果/日付/ホワイトリスト
- Googleは検索結果に表示させるコンテンツの種類をコントロールできるようです。例えば、「〇〇」というクエリでは、検索結果にニュース2件、記事3件、ECサイト5件などを表示し、それはタイミングによって内訳が変わることもあります。検索結果は常に確認すると良いでしょう。
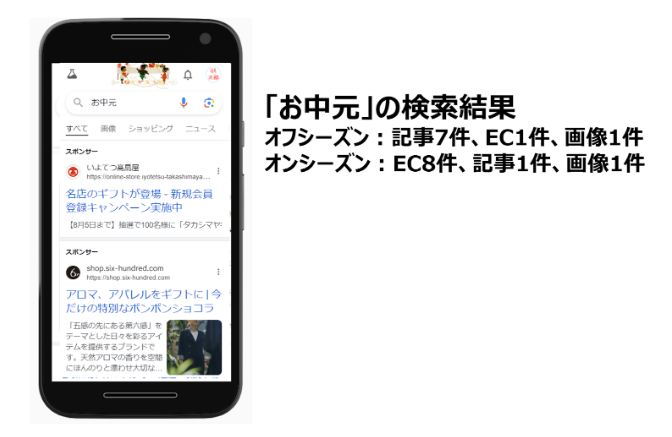
- Googleは日付を見ています。URL、構造化データ、ページのHTML、XMLサイトマップのデータ(特に日付)は、一致させることが必要です。特に日付をURLに入れると(例:/2012/12/)、古くなったときに懸念がありますので入れないほうがいいかもしれません。
- Googleはホワイトリスト(コロナ関連や選挙関連などで、信頼できるサイトのリスト)を持っています。これによって信頼性の低いサイトが検索結果にあまり露出しませんので、ユーザーにとってはよいことです。
感想
今回のニュースが大きな反響を呼んだ理由の一つは、これまでSEO業界で正しいとされていた情報との差異が大きかったためだと思います。例えば、Googleはドメインオーソリティ的な指標はないと言っていましたが、ドキュメントには「siteAuthority」という属性が存在しています。また、ページエクスペリエンスシグナル以外のランキングにはChromeデータを使っていないと言っていましたが、Chrome関連の属性も多数見られます。SEO施策の際には、Googleの発言を100%信用するのではなく、自分たちの経験、そして常にユーザーのことを考えて行うことが重要です。
また、Googleは思ったより賢くないかもしれません。そのため、予想以上に多くのデータを収集し、重み付けを行い、人間のように良いコンテンツと悪いコンテンツを判定できるよう努力しているように感じます。今後は、自分がGoogleのエンジニアやデータサイエンティストだったら、どうやってページの品質を正しく評価できるかを改めて考えていきたいです。
今回の漏洩で残念に感じたことは、Googleがクリック数やリンク数、権威性などの指標を重視しているということは、有名なブランドに有利に働いているのではないかということです。実際、ユーザーも有名なブランドサイトは検索結果でクリックしやすい傾向がありますよね。今回は「smallPersonalSite」という小規模サイトに関する属性を巡ってGoogleを批判する声が多いですが、中小企業や個人のサイトに対して、大手企業とは異なる重み付けを使うべきだと思います。
最後に、今回は主に検索のことを紹介しましたが、ドキュメントの原文にはニュースやローカル関連もあります。ニュースSEO担当者やローカルSEO担当者などの方はぜひ原文を読んでみてください!
参考情報
1.https://ipullrank.com/google-algo-leak
2.https://searchengineland.com/how-seo-moves-forward-google-leak-442749
3.https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/
4.https://blog.marketmuse.com/google-content-warehouse-api-leak/
5.https://cloudonair.withgoogle.com/events/next-tokyo/watch?talk=d1-db-01
6.https://www.searchenginejournal.com/extending-your-schema-markup-from-rich-results-to-a-knowledge-graph/511958/
7.https://www.justice.gov/atr/us-and-plaintiff-states-v-google-llc-2020-trial-exhibits
8.https://www.blindfiveyearold.com/its-goog-enough
9.https://events.goldcast.io/splash/052be756-fba8-4bfc-aa9d-c6eafe63262e
10.https://www.semrush.com/blog/semantic-search/