米国時間2023年10月11日-12日、ニュースSEOに特化したカンファレンス「News & Editorial SEO Summit 2023」がオンラインで開催されました。
代理店側のSEO専門家や、大手新聞社のインハウスSEO専門家が集まり、様々な視点から新聞・雑誌に関するSEOの知見や経験が共有されました。
本コラムでは、セッションの中から非常に興味深いと感じたテクニカルSEOやインハウスSEO、Google Discoverに関する内容を紹介します。
- セッション1:メディアサイトのためのテクニカルSEO【2023年版】
- セッション2:ニュースSEOがどのように編集局へ影響を与えるか
- セッション3:自然検索からの流入を失わずにGoogle Discoverからの流入を獲得する
- まとめ
セッション1:メディアサイトのためのテクニカルSEO【2023年版】
by Barry Adams(@PolemicDigital)
メディアサイトのテクニカルSEOには、例えばインデックスのスピード強化や、ニューストピックオーソリティを意識しながら最適化するなどの特性があります。
そのため、まずはこのカンファレンスを立ち上げたSEOのエキスパート、Barry Adams氏のテクニカルSEOセッションを紹介していきたいと思います。
【基礎編】
メディアSEOの担当者が知っておくべきテクニカルSEOの基礎は以下になります。
●クローリングのベストプラクティス●
- ページの平均応答時間が600ミリ秒以下になっているかをSearch Consoleでチェックする。
※シュー補足:600ミリ秒はPageSpeed Insightsの基準と一致している。600ミリ秒を超えると、赤の三角の警告アイコンが表示されることが確認できる。

参照:https://developer.chrome.com/docs/lighthouse/performance/server-response-time/
- URL構造を簡潔にする。内部リンクにトラッキングパラメータを使わない。
理由:Googleはcanonicalタグを無視することがあり、パラメータ付きのURLもインデックスしてしまう可能性がある。パラメータ付きのURLが検索結果に出てしまうと、ページへの評価が分散してしまうため効果測定が難しくなる。
- ページリソース(JavaScript、CSS、フォントファイルなど)はクロールバジェットを消化するので、軽くすると良い。
- ページネーションのベストプラクティスは、「次へ」のボタンに次ページへのリンクを設置すること。
理由:トピックオーソリティの観点から、良質なコンテンツの数が多いとGoogleに良く評価される傾向があるので、2ページ目以降もクロールできるようにすると良い。
- HTTPステータスコードを正しく設定する。
例:ページがなくなった時は404or410、リダイレクト時は301or302、インデックスしたいページは200にする
- AdsBotはクロールバジェットを消化してしまうことがあるため、Barry氏のサイトはAdsBotをブロックしている。
●インデクシングのベストプラクティス●
Googleのインデクシングには色々なモジュールがある。
| モジュール | 特徴 |
| HTML Lexer | HTMLをトークン化する。 いわゆる、きれいでないコードを一掃する。特にjsで生成されたコード。 |
| Parser | インデクシング用のHTMLコンテンツを抽出する。 セマンティックHTMLを使うと、Googleが理解しやすい。 |
| Canonicaliser | 正規バージョンを決定する。 正規化のシグナルはcanonicalタグだけではなく、内部リンクやサイトマップからのリンクも含まれる。 |
| Pageranker | リンクの価値を計算する |
※シュー補足:HTML LexerについてこちらのGoogle公式のポッドキャストにて言及されていたので、ご参考ください。
- Googleがより認識できるよう、セマンティックHTMLを推奨している。また、クライアントサイドのJavaScriptを使用してコンテンツを読み込むことは避けるべき。
理由:Googleはレンダリングできても、ニュース記事の場合は速度を重視するのでレンダリングしない可能性が高い。なぜなら、レンダリングは時間がかかるからだ。ニュースの場合はHTMLコードのクローリングのみと考えたほうがよい。
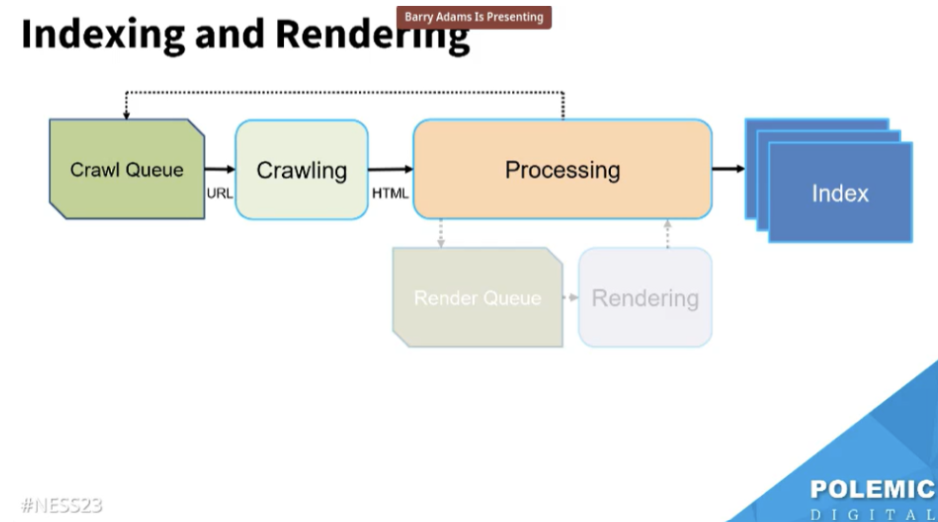
※シュー補足:Barry氏は速報・新着ニュースの場合を指していると思います。GoogleのGary氏によれば、最終的にはGooglebotは再度訪れてニュースページをレンダリングするようです。
参照:https://www.seroundtable.com/google-news-render-search-index-35113.html
- 記事のタイトルに<h1>タグを推奨する。
✕ <div class=”headline”>記事のタイトル</div>
〇 <h1>記事のタイトル</h1>
- HTMLの<head>セクションを簡潔にし、title、meta description、og(オープングラフ)メタタグ、構造化データなど重要な要素を上部に置いておく。
- <body>セクションにおいては、できればh1から記事の最後まで、コードが途切れないようにする。SNSシェアアイコン、SNSの埋め込み、関連記事ブロックなどは記事部分のコードの前か後に置くと良い。
- 構造化データの設置を推奨:記事ページにNewsArticle、筆者紹介ページにPersonを指定する。
【推測編】
●クローリング、インデクシングにおける見解(非公式)●
Barry氏はGooglebotは3種類あると推測している:リアルタイムクローラー、レギュラークローラー、レガシーコンテンツクローラー
| クローラー | 特徴 |
| リアルタイムクローラー | ・VIPページをクロールする ※VIPページとは、頻繁に更新されるページまたは権威性が高いページ 例:ニュースサイトのホームページや重要なセクション ・価値のある新しいコンテンツを常に探している ・一度訪れたページを再度クロールすることはあまりない |
| レギュラークローラー | ・多くのサイトを巡回するクローラー ・ページリソースをクロールするGooglebotと同じかもしれない |
| レガシーコンテンツクローラー | ・VUPページをクロールする ※VUPページとは、価値が低いページやあまり更新されないページ ・4XXエラーページを再度クロールする たまに古いリダイレクトURLを再度クロールする可能性もある |
クローラーに併せて、インデクシングにも3種類あるとBarry氏は推測している。
| インデックスデータ保存 | 特徴 |
| RAM | ・リアルタイムクローラーがクロールしたページを保存する 例:ニュース、人気なコンテンツ ・検索したときのレスポンス時間が最も早い |
| SSD | ・レギュラークローラーがクロールしたページを保存する 例:2ページ目以降の検索結果 ・RAMよりGoogle的にはコストが低い ・検索したときのレスポンス時間はRAMほど速くはない |
| HDD | ・レガシーコンテンツクローラーがクロールしたページを保存する 例:たまに検索結果に表示されるページ |
ニュースが公開されたら、まずはリアルタイムクローラーが来てクロールする。
その後、もしニュースの内容が修正されても、リアルタイムクローラーが再度クロールしに来る可能性は低い。
次はレギュラークローラーの出番。
ただ、レギュラークローラーはリアルタイムクローラーより遅いので、レギュラークローラーが来るまでに修正された内容は検索結果で反映されないかもしれない。
→ そのため、ニュースを公開する前にSEOを完了させましょう。
ただ、リアルタイム配信のブログ記事(LiveBlogPosting)の場合は気にしなくて良いかも。
【その他の面白いポイント】
- Barry氏はLLMs(大規模言語モデル)をブロックすることを強く推奨している。理由としては、ニュース記事1つをとってもこれは立派な知的財産であるため、LLMの学習に用いるのであれば許可が必要だと考えるからである。

最新のブロックルールを以下にご確認ください。
- Googleの6月のサイトマップに関するブログ記事へのコメント
changefreq、priorityはGoogleが使わないため、無視して良い。逆に、使うとサイトマップのサイズが大きくなってしまう。サイトマップに必要なのは、URLとlastmodのみだ。 - Googlebotは「記事の日付と混乱させないために、関連記事ブロック内の記事の日付は同じ画面には表示させない方が良い」と推奨している。これに対して、Barry氏は本当はUXの観点からはよくないと思うが、Googleの推奨なので注意してくださいとコメントした。
参照:https://developers.google.com/search/docs/appearance/publication-dates
- CNETのニュースへのコメント
単に古いという理由だけでコンテンツを削除すべきではない。削除すべきなのは、低品質なコンテンツだ。
理由:トピックオーソリティには良質なコンテンツの数が関係している。トピックオーソリティが高ければ高いほど、検索結果での露出度も高くなる。古いからといって良質なコンテンツを削除してしまうと、トピックオーソリティが下がってしまう可能性がある。
※シュー補足:CNETは、自社のコンテンツが新鮮で関連度が高いことをGoogleに示すため、たくさんの古い記事を削除していることが報じられ、Googleはそのようなベストプラクティスを推奨したことはないと注意喚起していました。
- Googleは「シンジケーションコンテンツはnoindexさせると良い」と推奨している。
これに対して、Barry氏はGoogleは重複コンテンツをまだ簡単には区別できないと考えており、配信先記事にnoindexを含めるのは基本的には不可能なので、自分のサイトの順位を上げたいのであれば、シンジケーション自体しないほうが良いとコメントした。
セッション2:ニュースSEOがどのように編集局へ影響を与えるか
by Claudio Cabrera(@CECabrera_)
ニューヨーク・タイムズ傘下のスポーツ専門メディア「ジ・アスレチック」の副社長Claudio Cabrera氏は、自社のSEOチームの仕事内容や、記者や編集者と連携する6つのポイントなどについて語りました。
【仕事内容】
SEOチームは4名の専門家で構成され、以下の項目に取り組んでいる。
- 公開日の選定において、大きな影響力を持っている。例えば、金曜日は一般的に流入が低下する傾向があるため、月曜日に全ての記事を公開するのではなく、一部の記事をあえて金曜日に公開することを社内提案する。
- インデックススピード
- 大見出し作成 & 最適化のトレーニング
- ウェブサイトの構造最適化において、エンジニアチームと連携する
- リンクの最適化
- SNSでの拡散を考慮する
- メインビジュアルの選定
- 読者に配信通知するかどうか
- 社内向けのデイリーレポート
- 社内向けの月次レポート
- コアウェブバイタル
- Google側の変化やアップデートに関するウィークリーレポート
- 毎日エバーグリーンコンテンツ(長期間人気のあるコンテンツ)をチェックする
- 自社のサイトパフォーマンス向上のため、様々な改善策を提案する
【記者や編集者と連携する6つのポイント】
Respect(尊敬): 日常的に記者や編集者からYESよりもNOとの回答を多く受けることがあるが、そのNOへの取り組み方が重要。それは、このNOが将来のYESへと繋がる可能性を秘めているからだ。
Read(読む): ウェブサイトやSEOの最適化にのみ焦点を当てるのはよくない。提案するトレンドのテーマが既に記者達側で取り上げられている場合、その提案は意味がなくなるだろう。そのため、読者目線で自社の報道や記事をしっかりと読むことが不可欠。
Reporting(報告): レポートを提出する際に、検索結果やトップニュースでの実績のリストアップだけでなく、その実績を得た理由を共有することが大事。具体的には、公開スピードが影響しているのか、競合が少ないからなのか、SEOの最適化の結果なのかといった要因を明示することが大切。
Relationships(関係性): 全ての編集者のSEO提案への考え方を把握する。
Recognition(承認): 上位獲得時には評価をし、獲得できなかった際には教育的なフィードバックを行う。良好な関係性の構築は、チームの成功にとって極めて重要だとClaudioさんは強調していた。
Readers(読者): 新聞社への提案を行う際、単に検索数だけで判断するのではなく、読者のニーズにどう対応するかを中心に考慮することが必要。
【その他の興味深い内容】
- Claudioさんのチームの経験から、質問形式の大見出しと読者が本当に知りたいと思うエバーグリーンコンテンツは、自然検索とDiscoverの両方で非常に効果的であるよう。
- Googleは独自性の強い深堀記事や文量が多くて長い記事を自然検索で高くランク付けしない傾向が見られる。対策として、Claudioさんのチームはこの深掘り記事の中でヒットしやすそうなポイントを取り上げ、短い記事を別途作成している。
- 記者や編集者にSEOの戦略や提案を行う場合、その数ヶ月前(記者や編集者が何を取り上げたいかを決める前)にアプローチする。例えば、NBAが10月に開始する場合、Claudioさんのチームは6月や7月頃に新しいニュース報道のアイデアを提案している。
セッション3:自然検索からの流入を失わずにGoogle Discoverからの流入を獲得する
By Lily Ray(@lilyraynyc)
昨今多くの新聞社にとってはGoogle Discoverからの流入が重要になっているのではないでしょうか。SEO専門家Lily Ray氏が自然検索の流入を失わずにGoogle Discoverの流入を獲得する方法をシェアしました。
【背景】
Lily氏のチームが多数の新聞社の案件を整理・分析し、Google Discoverに表示されるコンテンツは以下のような特徴があるものが多いことを発表した。
- 感情を煽るような釣りタイトル(クリックベイト)
- 大見出しに答えを入れない
- 更新頻度が非常に高い(例:本日のランキング、今週のランキング)
- ドラマやゴシップなどのエンターテインメント関連、または内容が薄いコンテンツ
しかし、これらのコンテンツは、例えば大見出しに答えを入れないのはSEO的に良くなく、自然検索からの流入を低下させるリスクがあるため、Google Discoverの対策を行う際には慎重に取り組む必要があると強調した。
【アドバイス①】
まずは、自社の流入データを分析する。そして、効果的と思われる戦略は引き続き活用する。
- 自然検索のデータとGoogle Discoverのデータを横並びさせて比較すると、新しい発見が得られるかも。
- 自然検索やSNSからの流入は獲得できているが、Google Discoverでのパフォーマンスが低いコンテンツを整理する。同様に、Google Discoverでは効果的で、自然検索やSNSで効かないコンテンツも整理する。
例として、Lily氏のお客様は「質問形式のタイトルは自然検索に、書き出しがエンティティのタイトル(例:ビヨンセが〇〇をした)はGoogle Discoverに効果的だ」という傾向を発見した。
【アドバイス②】
ニュースは大見出しが大事、h1やtitleタグを工夫する。
ニューヨーク・タイムズ(NYT)の事例が紹介された。NYTは、h1はクリックしたくなるような「この店で買ったスパイスで、何でも美味しくなる」という見出し、titleタグは「七味唐辛子で、何でも美味しくなる」という異なる文言にした。これは、h1大見出しはよくGoogle discoverで表示され、titleタグは自然検索結果で表示される傾向があるためである。

【アドバイス③】
Google Discoverと自然検索の対策ポイントに一部違いがあるため、Google Discover用とSEO用のコンテンツは、異なるサブドメインや完全に別のルートドメインで掲載することをお客様に提案する。
【アドバイス④】
YoutubeショートやYoutube動画はDiscoverの流入に非常に役立つ。形式はサイトに埋め込むことも、Youtubeへアップロードすることも効果的なよう。
【アドバイス⑤】
Lily氏のクライアントの中にはウェブストーリーを作成することが役立っている方がいるようだが、ウェブストーリー自体は流入につながらないこともあるので、ウェブストーリーからコンテンツへのリンクを必ず含める。
まとめ
このカンファレンスは2021年から開催されたもので、まだ歴史が浅いです。
講演者はSEOコミュニティで有名な方々が多いとはいえ、正直私は半信半疑でした。
しかし、今まで参加してきたSMXやBrightonSEOと比べ、NESSはテーマについて深掘りできること、講演者へのQ&Aが充実していることなど、学びを得ることの多いカンファレンスだったと思います。
メディアサイトはインデクシングのスピードが大事と聞いたことがありましたが、それを今回かなり実感しました。
ニュースSEO担当者もテクニカルSEOを学ぶ価値は大いにあると考えます。
来年も同様に素晴らしいラインナップであれば、また参加してみようと思います。






